Pracowania Programowania
JSON & XML
Autor: Tomasz Ziętkiewicz
Uwaga! Kod do tych zajęć znajduje się na gałęzi serialization w repozytorium https://github.com/WitMar/PRA2018-2019 . Kod końcowy w gałęzi serializationFinal.
JSON
JSON (JavaScript Object Notation) http://www.json.org/ to lekki, tekstowy format wymiany danych.
Jest oparty na podzbiorze języka JavaScript.
Powszechnie wykorzystywany do przechowywania i przekazywania ustrukturyzowanych danych w postaci tekstowej.
Właściwości JSON-a:
czytelny dla człowieka
szeroko rozpowszechniony - biblioteki dla każdego języka (lista na http://www.json.org)
Przykład JSON
{
"artist": "Pink Floyd",
"title": "Dark Side of the moon",
"year": 1973,
"tracks": [
{
"track#": 1,
"title": "Speak to Me/Breathe",
"length": "3:57",
"music": ["Mason"]
},
{
"track#": 2,
"title": "On the run",
"length": "3:50",
"music": ["Waters", "Gilmour"]
}
]
}Przykład z życia: API rowerów miejskich
Składnia JSON
Dwie struktury danych:
object (obiekt, słownik, mapa) zbiór par klucz-wartość
{
"title": "Dark Side of the Moon",
"year": 1973,
"tracks#": 9
}
- array (tablica, lista)
uporządkowany zbiór wartości
{
"name":"John",
"age":30,
"cars":[ "Ford", "BMW", "Fiat" ]
}
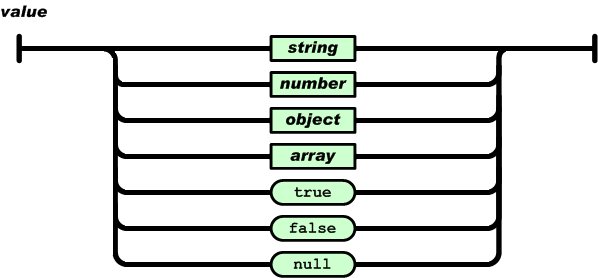
Siedem typów wartości:
XML
XML (Extensible Markup Language) - język znaczników (markup language), który podobnie jak JSON umożliwia serializację i wymianę strukturalnych danych w postaci tekstowej.
Składnia XML
W dokumencie XML możemy wydzielić zawartość (content) i * znaczniki (markup).
Znaczniki znajdują się między parami znaków "<" i ">" lub "&" i ";".
Treść dokumentu to wszystkie znaki, które nie są znacznikami.
Tagi
tagi początku elementu:
<album>tagi końca elementu:
</album>tagi puste (bez zawartości):
<album />Element
Element rozpoczna się tagiem początku, kończy tagiem końca elementu, albo jest pustym tagiem.
Pomiędzy tagami znajduje się zawartość elementu, którym może być albo zwykły tekst, albo zagnieżdżone elementy.
Tagi początkowy i pusty mogą zawierać atrybuty, czyli pary klucz-wartość.
Klucz podajemy jako text bez cudzysłowów, wartości zawsze w cudzysłowie.
<track number="3" title="Time" length="3:57">
Ticking away the moments that make up a dull day
You fritter and waste the hours in an offhand way
Kicking around on a piece of ground in your home town
Waiting for someone or something to show you the way
</track>Komentarze
Komentarze znajdują się między znacznikami "<!--" i "-->".
Przykład XML
<?xml version="1.0" encoding="UTF-8"?>
<album title="Dark Side of the Moon" year="1973">
<track number="1" title="Speak to Me/Breathe">
Breathe, breathe in the air
Don't be afraid to care
Leave but don't leave me
Look around and choose your own ground
For long you live and high you fly
Smiles you'll give and tears you'll cry
And all you touch and all you see
Is all your life will ever be
</track>
<track number="2" title="On the run" />
<track number="3" title="Time" length="3:57">
Ticking away the moments that make up a dull day
You fritter and waste the hours in an offhand way
Kicking around on a piece of ground in your home town
Waiting for someone or something to show you the way
</track>
</album>Życiowy przykład: API rowerów miejskich, XML
Serializacja / Deserializacja
Serializacja - proces polegający na przekształceniu struktur danych albo stanu obiektu do sekwencyjnej formy, która umożliwa zapisanie lub przesłanie tych danych i potencjalnie odtworzenie struktur danych lub obiektów w późniejszym czasie/przez inny proces/komputer (deserializację).
Na przykład, serializacja może polegać na zapisie do pliku w formacie JSON obiektów wygenerowanych przez nasz program, w celu późniejszego wczytania tych obiektów z powrotem do programu w celu kontynuowania obliczeń.
JSON i XML są przykładami formatów dobrze nadających się do serializacji danych w sposób czytelny dla człowieka.
Można również serializować dane w postaci binarnej, niezrozumiałej dla człowieka.
Jackson
Jackson - zestaw narzędzi do przetwarzania danych dla Javy ("suite of data-processing tools for Java").
Głównym komponentem jest generator/parser JSON, pozwalający m.in. na deserializację/serializację do/z JSON z/do Javy.
Posiada liczne moduły dodające obsługę innych formatów danych, m.in. XML, YAML czy CSV.
Strona domowa projektu nie działa, ale projekt jest aktywnie rozwijany na GitHub. Zarchiwizowana wersja strony domowej.
Zadanie 1: Serializacja do JSON przez Jackson
Dodaj bibliotekę Jackson do pom.xml
Wskazówka: Odpowiedni wpis znajdzie w dokumentacji w repozytorium GitHub modułu.
Stwórz dwóch pracowników (obiekty klasy Employee). Niech jeden pracownik będzie przełożonym a drugi jego podwładnym.
Każdemu z pracowników przypisz adres.
Za pomocą om.fasterxml.jackson.databind.ObjectMapper zapisz (dokonaj serializacji) obiektu przełożonego do pliku json.
Przykłady:
Zadanie 2: Deserializacja z JSON
Odtwórz obiekt przełożonego z utworzonego w zadaniu 1. pliku JSON. Zmień przełożonemu wynagrodzenie i zapisz (dokonaj serializacji) do pliku json.
Zadanie 3: annotacje
W języku Java dla zapisu nazwy pól klasy przyjmuje się konwencję notacji lowerCamelCase.
W JSON nie ma przyjętego standardu notacji (dyskusja na StackOverflow).
Domyślnie pola w JSONie wygenerowanym przez Jackson/Gson mają takie same nazwy jak pola w klasie, którą serializujemy. Dodaj do modelowanych klas annotacje zmieniającą nazwę salary na "pieniadz" oraz adnotacje do ignorowania pola "pesel" przy serializacji.
Wskazówka: Skorzystaj z dokumentacji.
Zadanie 4: deserializacja typów generycznych
Stwórz plik json zawierający listę kilku pracowników. Wczytaj tę listę do kolekcji ArrayList<Employee>.
Wskazówka: Skorzystaj z 3 minute tutorial.
Jackson XML
Jackson posiada moduł rozszerzający go o obsługę formatu XML. Aby użyć XML zamiast JSON wystarczy zmienić "ObjectMapper" na XmlMapper":
ObjectMapper xmlMapper = new XmlMapper();http://www.baeldung.com/jackson-xml-serialization-and-deserialization
Zadanie 5: XML
Korzystając z istniejącej klasy JacksonSerialization zmodyfikuj ją, albo stwórz nową klasę tak, żeby umożliwić serializację / deserializację do/z formatu XML. Dodaj do katalogu main/resources pliki xml odpowiadające istniejącym już plikom json.
Wskazówka: Nie musisz tworzyć zawartości plików xml samodzielnie, możesz wygenerować je za pomocą odpowiednich metod.
Wskazówka: Pamiętaj żeby dodać bibliotekę do pom.xml. Odpowiedni wpis znajdziesz w repozytorium GitHub modułu XML.
Zadanie 6: Joda Time
Dodaj do klasy Employee pole
DateTime birthDatezawierające datę urodzenia pracownika.
Dodaj na nim adnotacje
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss.SSSZ")Spróbuj dokonać serializacji a następnie deserializacji obiektu tak zmodyfikowanej klasy.
Wskazówka: Możesz potrzebować modułu jackson-datatype-joda.
Potrzebujesz zarejestrować w mapperze moduł Joda.
Zadanie 7: rekurencyjne odwołania
Zauważ, że w JSONie wypisywane są całe obiekty wraz z zależnościami. Co stałoby się gdyby pracownik X miał podwładnego Y którego podwładnym byłby znów X? Otrzymalibyśmy nieskończoną rekurencję i błąd serializacji. Żeby tego uniknąć możemy zastosować adnotację:
Uncomment 65 line in ModeObjectCreator.java
@JsonIdentityInfo(generator=ObjectIdGenerators.IntSequenceGenerator.class, property="refId", scope=Employee.class) public class Employee { ... }
Która spowoduje, że obiekty wypisywane będą tylko raz, a przy wielokrotnych odwołaniach zostanie zastosowane Id jako referencja.
Więcej na ten temat:
http://www.baeldung.com/jackson-bidirectional-relationships-and-infinite-recursion
Lambda Expressions
Tradycyjnie w Javie do przechodzenia po kolekcjach korzystamy z iteratorów jawnie wyspecyfikowanych w kodzie:
List<String> names = new ArrayList<>();
for (Student student : students) {
if(student.getName().startsWith("A")){
names.add(student.getName());
}
}Wykorzystując strumienie korzystamy z tzw. wewnętrznych iteracji, to znaczy logika iteracji po elementach jest dla nasz ukryta a skupiamy się na ich przetwarzaniu.
List <string> names = students.stream()
.map (student :: getName)
.filter (Name-> name.startsWith("A"))
.collect (Collectors.toList());Operacje na strumieniach
Operacja na strumieniach dzielimy na pośrednie i końcowe (terminalne). Operacje pośrednie zwracają jako wynik działania strumień. W powyższym przykładzie takimi operacjami są map i filter. Operacje terminalne kończą przetwarzanie, zwykle agregują one wyniki, zliczają wartości, albo też nic nie wykonują (np. operacja foreach może być terminalna). Powyżej przykładem takiej operacji jest collect.
Dla operacji numerycznych stworzono specjalne strumienie IntStream, DoubleStream, and LongStream.
IntStream.rangeClosed(1, 10).forEach(num -> System.out.print(num));
// ->12345678910
IntStream.range(1, 10).forEach(num -> System.out.print(num));
// ->123456789Budowa strumieni
Stream stałych i elementów tablicy:
Stream.of("This", "is", "Java8", "Stream").forEach(System.out::println);
String[] stringArray = new String[]{"Streams", "can", "be", "created", "from", "arrays"};
stringArray.forEach(System.out::println);Elementy strumieni
Filter
Wybiera elementy ze strumienia względem danego warunku
students.stream()
.filter(student -> student.getScore() >= 60)
.collect(Collectors.toList());Map
Zmienia przetwarzany element na coś innego, czyli pobiera element jednego typu i zwraca element innego typu. W praktyce najczęściej służy do wyciągnięcia jakiś atrybutów z obiektów.
students.stream()
.map(Student::getName)
.forEach(System.out::println);The Student::getName jest skrótowym odwołaniem się do metody z klasy. Czyli na obiekcie typu Student, który przyjdzie ze streama wywołujemy metodę getName().
Równoważnie możemy zapisać taki strumień jako:
students.stream()
.map(student -> student.getName())
.forEach(System.out::println);Distinct
Usuwa powtórzenia
students.stream()
.map(Student::getName)
.distinct()
.collect(Collectors.toList());Limit
Ogranicza liczbę elementów w strumieniu do podanej liczby.
Sorted
Sortuje elementy w naturalnym dla nich porządku.
students.stream()
.map(Student::getName)
.sorted()
.collect(Collectors.toList());Z pomocą klasy Comparator możemy definiować sortowania różnego typu
//Sorting names if the Students in descending order
students.stream()
.map(Student::getName)
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
//Sorting names if the Students in descending order
students.stream()
.map(Student::getName)
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
//Sorting students by First Name and Last Name both
students.stream()
.sorted(Comparator.comparing(Student::getFirstName).
thenComparing(Student::getLastName))
.map(Student::getName)
.collect(Collectors.toList());
//Sorting students by First Name Descending and Last Name Ascending
students.stream()
.sorted(Comparator.comparing(Student::getFirstName)
.reversed()
.thenComparing(Student::getLastName))
.map(Student::getName)
.collect(Collectors.toList());FlatMap
Działa podobnie jak mapa, tylko jako wynik zwraca strumień przetworzonych elementów.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
List<List<Integer>> mapped =
numbers.stream()
.map(number -> Arrays.asList(number -1, number, number +1))
.collect(Collectors.toList());
System.out.println(mapped); //:> [[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]]
List<Integer> flattened =
numbers.stream()
.flatMap(number -> Arrays.asList(number -1, number, number +1).stream())
.collect(Collectors.toList());
System.out.println(flattened); //:> [0, 1, 2, 1, 2, 3, 2, 3, 4, 3, 4, 5]Elementy Terminalne
Match
Match stosujemy gdy interesuje nas występowanie w strumieniu elementu o danych własnościach.
//Check if at least one student has got distinction
Boolean hasStudentWithDistinction = students.stream()
.anyMatch(student -> student.getScore() > 80);
//Check if All of the students have distinction
Boolean hasAllStudentsWithDistinction = students.stream()
.allMatch(student -> student.getScore() > 80);
//Return true if None of the students are over distinction
Boolean hasAllStudentsBelowDistinction = students.stream()
.noneMatch(student -> student.getScore() > 80);Find
Pozwala znajdować obiekt w strumieniu o danych włanościach, możemy wybrać dowolny dopasowany obiekt lub pierwszy dopasowany.
//Returns any student that matches to the given condition
students.stream().filter(student -> student.getAge() > 20)
.findAny();
//Returns first student that matches to the given condition
students.stream().filter(student -> student.getAge() > 20)
.findFirst();Reduce
Pozwala zredukować strumień danych do pojedynczej wartości.
//Summing without passing an identity
Optional<integer> sum = numbers.stream()
.reduce((x, y) -> x + y);
//Product without passing an identity
Optional<integer> product = numbers.stream()
.reduce((x, y) -> x * y);Collect
Zbiera elementy strumienia w listę.
students.stream()
.filter(student -> student.getScore() >= 60)
.collect(Collectors.toList());Ważne: Collect zwraca nowy obiekt! Nową listę, mapę, zbiór etc. ale wartości są te same co w przetwarzanej kolekcji.
RemoveIf
Usuwanie z kolekcji elementów spełniających warunek.
students.removeIf(student -> student.getScore() >= 60)Stateless
W obrębie strumienia nie możemy zmieniać wartości elementów po których się poruszamy.
Zalecane! W domu postaraj się wykonać zadania z repozytorium: