Pracownia Programowania
ORM
Uwaga! cały kod do Zadania 7 włącznie znajduje się na gałęzi hibernateStart w repozytorium https://github.com/WitMar/PRA2018-2019 . Kod końcowy w gałęzi hibernateEnd.
Jeżeli nie widzisz odpowiednich gałęzi na GitHubie wykonaj Ctr+T, a jak to nie pomoże to wybierz z menu VCS->Git->Fetch.
ORM
ORM to skrótowe oznaczenie dla "mapowanie obiektowo-relacyjne" (od angielskiego Object-Relational Mapping). Chodzi więc o zamianę danych w postaci tabelarycznej (relacji w bazie danych) na obiekty, albo w drugą stronę. Jest nowoczesnym podejściem do zagadnienia współpracy z bazą danych, wykorzystującym filozofię programowania obiektowego.
Elementy ORM
1. API do zarządzania trwałością obiektów2. Mechanizm specyfikowania metadanych opisujących odwzorowanie klas na relacje w bazach danych3. Język lub API do wykonywania zapytań. Najpopularniejsza implementacja technologii odwzorowania obiektowo-relacyjnego dla aplikacji Java to Hibernate (dla C# to LinQ)
Zależności
Żeby korzystać z Hibernate potrzebne nam będzie na pewno pakiet hibernate-core oraz sterownik bazy danych.
<!-- Hibernate resources -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.2.1.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.2.Final</version>
<classifier>tests</classifier>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.3.0</version>
</dependency>
<!-- Database driver-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.1.1</version>
</dependency>W naszym projekcie będziemy korzystać z bazy HSQL (bazy w pamięci) ale w domu proszę uruchomić przykład z PostgreSQL lub jakąś bazą dostępną online np:
Zadanie 1
Dodaj zależności do pliku pom.xml.
Konfiguracja Hibernate
Konfiguracje Hibernate zapisujemy w pliku hibernate.cfg.xml, hibernate.properties lub persistence.xml .
Uwaga! W zależności od tego z jakich elementów korzystamy biblioteka przy wywołaniu szuka automatycznie określonych plików w ścieżce projektu w celu odnalezienia konfiguracji.
W pliku musimy wyspecyfikować:
szczegóły dostępu do bazy danych, adres, hasło, user, lokalizacja,język stosowanych zapytań sql,ew. listę klas mapowanych na tabele baz danychdialect określa jak hibernate ma komunikować się z bazą danychshow_sql - true pokaże nam zapytania SQL tworzone przez hibernate (głównie do debugowania).hbm2dll określa sposób zachowania względem schematu bazy danych. create oznacza że tworzymy za każdym razem schemat od nowa. Gdy już raz go stworzymy polecam zmienić wartość na validate lub update - ale update nie jest polecany gdyż może powodować dziwne błędy jak "table not found".
Przykładowe ustawienia dostępu do bazy danych dla bazy PostgreSQL:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1" xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="hibernate-dynamic" transaction-type="RESOURCE_LOCAL">
<properties>
<!-- Configuring JDBC properties -->
<property name="javax.persistence.jdbc.url" value="jdbc:postgresql://localhost:5432/postgres"/>
<property name="javax.persistence.jdbc.user" value="postgres"/>
<property name="javax.persistence.jdbc.password" value="postgresql"/>
<property name="javax.persistence.jdbc.driver" value="org.postgresql.Driver" />
<!-- Hibernate properties -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
<property name="hibernate.format_sql" value="false"/>
<property name="hibernate.show_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>Uwaga! żeby uruchomić program z powyższymi ustawieniami w domu powinieneś mieć zainstalowany serwer PostgreSQL lub zmienić adres serwera w ustawieniach. Informacje o instalacji PostgreSQL powinieneś łatwo znaleźć w internecie.Do podejrzenia danych w bazie postgresql polecam wykorzystać program pgAdmin.
Konfiguracja wykorzystująca uczelnianą bazę PostgreSQL:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1" xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="hibernate-dynamic" transaction-type="RESOURCE_LOCAL">
<properties>
<!-- Configuring JDBC properties -->
<property name="javax.persistence.jdbc.url" value="jdbc:postgresql://psql.wmi.amu.edu.pl:5432/mw?ssl=true&sslfactory=org.postgresql.ssl.NonValidatingFactory"/>
<property name="javax.persistence.jdbc.user" value="mw"/>
<property name="javax.persistence.jdbc.password" value="riustsdardswify"/>
<property name="javax.persistence.jdbc.driver" value="org.postgresql.Driver" />
<!-- Hibernate properties -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
<property name="hibernate.format_sql" value="false"/>
<property name="hibernate.show_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>Na zajęciach wykorzystywać będziemy bazę HSQL uruchamianą w pamięci komputera:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1" xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="hibernate-dynamic" transaction-type="RESOURCE_LOCAL">
<properties>
<!-- Configuring JDBC properties -->
<property name="javax.persistence.jdbc.url" value="jdbc:hsqldb:mem:PUBLIC;sql.syntax_ora=true"/>
<property name="javax.persistence.jdbc.user" value="sa"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="org.hsqldb.jdbcDriver" />
<!-- Hibernate properties -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.format_sql" value="false"/>
<property name="hibernate.show_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>Zadanie 2
Dodaj do katalogu resources podkatalog META-INF a w nim plik persistence.xml wklej do niego powyższą zawartość.
Mapowanie - adnotacje
Oznaczenie odwzorowania między tabelami bazy danych a klasą realizowane jest za pomocą mechanizmu adnotacji.
@Entity adnotacja służąca do określenia, że dana klasa ma być odwzorowana na encję bazy danych.@Table określa właściwości tabeli (np. nazwę, definicja ograniczeń itp.), jeżeli nie będzie tej adnotacji nazwą tabeli będzie nazwa klasy@Id oznaczamy klucz główny tabeli@Column określa właściwości kolumny tabeli (np. nazwę, czy musi być unikalne, czy może być puste), gdy nie jest zdefiniowana kolumna będzie miała taką nazwę jak pole klasy.@GeneratedValue oznacza że wartość tego pola będzie automatycznie generowana
package hibernate.model;
import javax.persistence.*;
@Entity
@Table(name = "EMPLOYEE", uniqueConstraints = {
@UniqueConstraint(columnNames = {"first_name","last_name"})})
public class Employee {
@Id @GeneratedValue
@Column(name = "id")
private int id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "salary")
private int salary;
@Column(name = "PESEL", nullable = false, unique = true)
private int pesel;
public Employee() {}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
public int getPesel() {
return pesel;
}
public void setPesel(int pesel) {
this.pesel = pesel;
}
}Zadanie 3
Dodaj pakiet hibernate i w nim pakiet model. Utwórz w środku powyższą klasę.
Stany encji
Oprócz samego mapowania obiektowo-relacyjnego, jednym z problemów, które Hibernate miał rozwiązać, jest problem zarządzania obiektami podczas wykonywania programu. Pojęcie "persisted context" jest rozwiązaniem Hibernata dla tego problemu. Persisted contex może być traktowany jako kontener lub pamięć podręczna pierwszego poziomu dla wszystkich obiektów, które zostały załadowane lub zapisane w bazie danych podczas sesji.
Każda instancja obiektu w aplikacji pojawia się w jednym z trzech głównych stanów w odniesieniu do kontekstu trwałości sesji:
* przejściowy (transient) - ta instancja nie jest i nigdy nie była związana z sesją; ta instancja nie ma odpowiednich wierszy w bazie danych; zwykle jest to tylko nowy obiekt, który stworzyłeś, aby zapisać do bazy danych;* persistent (managed) - ta instancja jest powiązana z unikalnym obiektem Session; po wykonaniu flush() do bazy danych, obiekt ten ma zagwarantowany odpowiedni spójny zapis w bazie danych;* odłączone (detached) - ta instancja była kiedyś podłączona do sesji (w stanie trwałym), ale teraz nie jest; instancja wchodzi w ten stan, jeśli usuniesz ją z kontekstu, wyczyścisz lub zamkniesz sesję lub przeniesiesz instancję przez proces serializacji / deserializacji.
Ważne jest, aby od samego początku zrozumieć, że wszystkie metody (persist, save, update, merge) nie powodują od razu odpowiednich instrukcji SQL UPDATE lub INSERT. Rzeczywiste zapisanie danych w bazie danych następuje po dokonaniu transakcji lub opróżnieniu sesji (flush()).
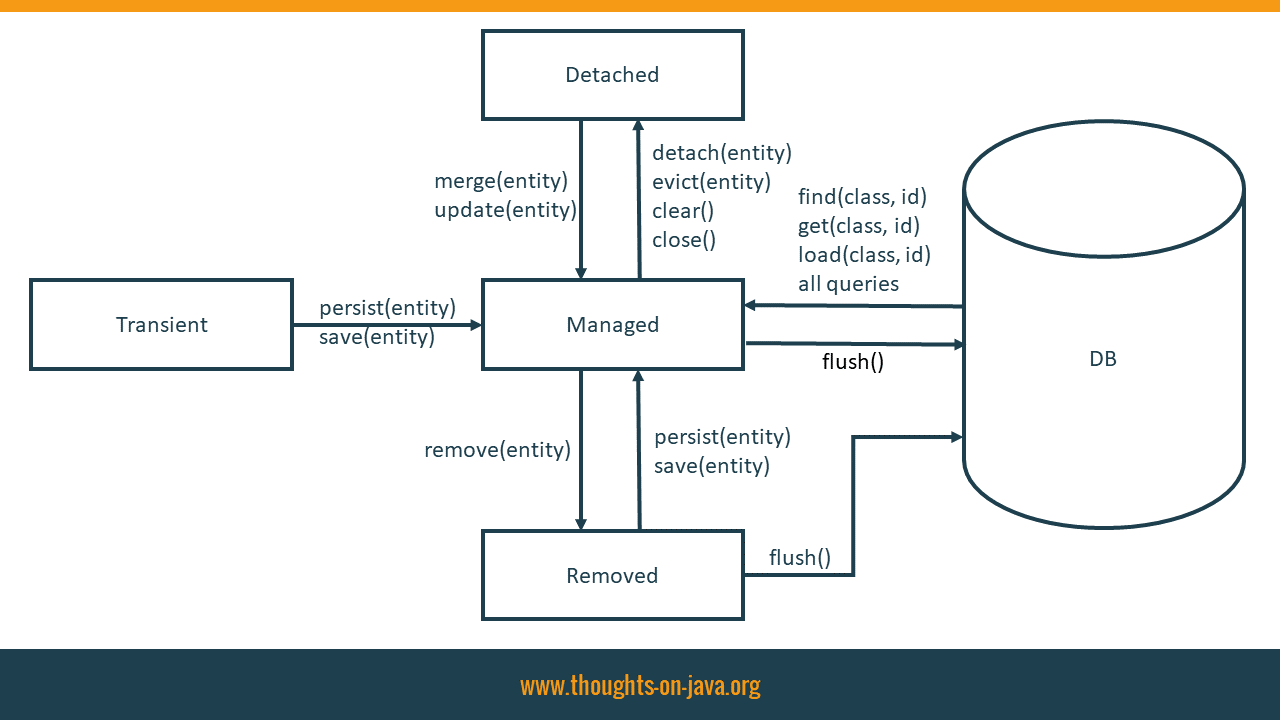
EntityManager vs SessionManager
Są dwa standardy obsługi sesji w hibernate, oparty na sesji i oparty na JPA z wykorzystaniem EntityManagera, dalej będziemy trzymać się drugiego standardu, EntityManagera ale ważne jest by wiedzieć, że oba istnieją.
Jeżeli w czasie pracy z kodem potrzebny Ci będzie obiekt Session możesz go pobrać korzystając z:
Session session = entityManager.unwrap(Session.class);Praca z Entity Managerem
Metoda find
Metoda find służy do pobierania jednego obiektu na podstawie jego klucza. Kluczem do wyszukania obiektu jest to pole, które posiada adnotację @Id. Przykładowe wywołanie:
entityManager.find(Employee.class, 1L);pobierze nam obiekt typu Employee, który ma id o wartości 1.
Jeśli metoda ta nie znajdzie danego obiektu w bazie danych, zwraca wartość null.
Metoda persist
Metody tej można używać do wstawiania nowego obiektu do stanu managed. Przykład:
Employee emp = new Employee();
entityManager.persist(emp);Przenosi nowy obiekt w stan managed. Metoda persist sprawia, że obiekt jest zarządzany, tzn. wszelkie zmiany, jakie na nim wykonany (w ramach jednej metody z adnotacją @Transactional lub metod, które taka metoda wywołuje) będą utrwalone w bazie danych.
Metoda merge
Metody tej można używać do wstawiania istniejącego obiektu ze stanu detached do stanu managed. Przykład:
Employee emp = new Employee();
entityManager.merge(emp);Metoda remove
Metoda remove służy do usuwania obiektów.
entityManager.remove(emp);Więcej informacji:
Przykład
Klasa zapisująca i czytająca element z bazy danych:
package hibernate;
import hibernate.model.Employee;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import javax.persistence.Query;
import java.util.List;
class Manager {
public static void main(String[] args) {
System.out.println("Start");
EntityManager entityManager = null;
EntityManagerFactory entityManagerFactory = null;
try {
//taka nazwa jak w persistence.xml
entityManagerFactory = Persistence.createEntityManagerFactory("hibernate-dynamic");
//utworz entityManagera
entityManager = entityManagerFactory.createEntityManager();
//rozpocznij transakcje
entityManager.getTransaction().begin();
Employee emp = new Employee();
emp.setFirstName("Jan");
emp.setLastName("Polak");
emp.setSalary(100);
emp.setPesel(100);
entityManager.persist(emp);
Employee employee = entityManager.find(Employee.class, emp.getId());
entityManager.remove(emp);
System.out.println("Employee " + employee.getId() + " " + employee.getFirstName() + employee.getLastName());
//zakoncz transakcje
entityManager.getTransaction().commit();
System.out.println("Done");
entityManager.close();
} catch (Throwable ex) {
System.err.println("Initial SessionFactory creation failed." + ex);
} finally {
entityManagerFactory.close();
}
}
}Własne zapytania
Aby wykonać zapytanie musimy najpierw je utworzyć za pomocą metody entityManager.createQuery a następnie pobrać wynik. Aby pobrać listę pracowników potrzebujemy wiec wykonać poniższy kod:
Query query = entityManager.createQuery("SELECT k FROM Employee k");
List<Employee> employees = query.getResultList();Jeśli nasze zapytanie zwraca tylko jeden element, możemy użyć metody query.getSingleResult();
Uwaga! Jeśli zapytanie do bazy danych nie zwróci wyników (wynik jest pusty), to:
metoda getResultList() zwróci wartość null!metoda getSingleResult() wyrzuci wyjątek (NoResultException)! (w sytuacji, kiedy mamy więcej niż jeden wynik, także otrzymamy wyjątek – NonUniqueResultException)
Obiekty zwrócone w zapytaniu są persisted to znaczy wszelkie zmiany na nich wykonane zostaną automatycznie zapisane do bazy danych (o ile znajdują się w ramach transakcji - obiekty poza transakcją nie zostaną zapisane).
Zadanie 4
Dodaj do klasy metodę getThemAll() pobierającą wszystkich pracowników.
JPA Query API
TypedQuery pozwala nam zdefiniować zwracany przez zapytanie typ. Np. gdy pytamy tylko o wartość jednej kolumny z tabeli.
TypedQuery<Employee> q2 =
em.createQuery("SELECT k FROM Employee k", Employee.class);Możemy także definiować zapytania z parametrami:
TypedQuery<Employee> query = entityManager.createQuery(
"SELECT c FROM Employee c WHERE c.lastName LIKE :name", Employee.class);
return query.setParameter("name", name).getResultList();Uwaga! Zwróć uwagę, że w zapytaniu użyto nazwy pola takiej jak nazwa w klasie a nie nazwa w bazie danych!
Przykłady zapytań:
Uruchomienie
Logowanie komunikatów
Zadanie 5
W pliku log4j.properties wklej linijkę
log4j.logger.org.hibernate=infoOkreśla ona poziom logowania komunikatów z hibernate. Zobacz różnice.
Zobacz co się zmieniło.
Transakcje
Uwaga! W Entity Managerze występują transakcje, oznaczają one tyle, że baza danych jest synchronizowana z elementami w pamięci tylko po zakończeniu (zakomitowaniu transakcji).
Ważne! W przypadku wystąpienia błędu w czasie przetwarzania transakcji żadna z operacji wykonanych w kodzie nie przeniesie się do bazy danych. Dlatego warto tworzyć osobne transakcje dla wybranych funkcjonalności.
Ważne jest to, że w Hibernacie operacje bazodanowe nie muszą w czasie zakończenia transakcji być wykonywane w porządku takim jak wystąpiły w kodzie. W szczególności powoduje to to, że w ramach jednej transakcji nie możemy usunąć a następnie dodać obiektu o takim samym kluczu głównym.
Zadanie 6
Zakomituj transakcję następnie usuń i dodaj pracownika o tym samym Id, zobacz co się stanie.
Zależności OneToOne
Pomiędzy tabelami baz danych występują zależności takie jak 1-1, 1-, *-.
Cel: Zadefiniuj zależność między obiektami - niech jeden obiekt będzie polem drugiego.
Czasem nasz model wymaga by oprócz typów prostych dana encja zawierała odnośnik do innej encji. Np. pracownika chcemy połączyć z jego adresem.
Zadanie 7
Zdefiniuj klasę address mającą pola city, street, nr, houseNumber, postcode. Tak by wszystkie oprócz houseNumber nie mogły być puste oraz kod miał co najwyżej 5 znaków (wszystkie pola powinny być typu String). Dodaj autogenerowany klucz główny.
@Entity
@Table(name = "ADDRESSES")
public class Address {
@Id
@GeneratedValue(generator = "gen")
@SequenceGenerator(name = "gen", sequenceName = "author_seq")
@Column(name = "id")
private int id;
@Column(nullable = false)
String street;
@Column(nullable = false)
String city;
@Column(length = 5, nullable = false)
String nr;
@Column(length = 5)
String housenr;
@Column(length = 5, nullable = false)
String postcode;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getNr() {
return nr;
}
public void setNr(String nr) {
this.nr = nr;
}
public String getHousenr() {
return housenr;
}
public void setHousenr(String housenr) {
this.housenr = housenr;
}
public String getPostcode() {
return postcode;
}
public void setPostcode(String postcode) {
this.postcode = postcode;
}
}Dodaj w klasie Employee pole, oraz zdefiniuj w Managerze address dla pracownika Jan.
@OneToOne(cascade = CascadeType.PERSIST)
@JoinColumn(name="Address_ID", referencedColumnName = "id")
Address address;Join column definiuje nazwy naszej kolumny oraz możemy zdefiniować nazwę kolumny z którą się łączy nasz element (kolumna ta musi być unikalna). Domyślnie łączymy się z kluczem głównym tabeli.
W OneToOne możemy definiować dodatkowe opcje, optional oznacza czy pole jest wymagane, CASCADE oznacza czy zmiany w polu adress danej osoby będą się propagować do tabeli Address (dostępne opcje MERGE, PERSIST, REFRESH, REMOVE, ALL).
Przykłady:
Pamiętaj by dodać do głównego kodu tworzenie Adresu dla pracownika i przypisaniu go do niego. Uwaga! Jeżeli chcemy żeby id generowane dla adresów były inne niż te dla pracowników to między @Id a @Column możemy wpisać:
@GeneratedValue(generator = "gen")
@SequenceGenerator(name="gen", sequenceName = "author_seq")Jeżeli potrzebowalibyśmy odwzorowania w obie strony między encjami musimy użyć adnotacji @MappedBy.
Zadanie 8
Zobacz co się stanie, gdy nie zdefiniujemy wartości dla jednego z obowiązkowych pól.
Co się stanie gdy dla obiektu w stanie persisted wykonamy:
emp.getAddress().setStreet(null);Zależności OneToMany
W wypadku gdy chcemy aby obie klasy miały dowiązanie do siebie (np dziecko do rodzica a rodzic do dziecka) to w jednej klasie definiujemy adnotacje @ManyToOne a w drugiej odwołujemy się do tego mapowania przez parametr "mappedBy").
@Entity
public class Parent {
// ...
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY)
private Set<Child> children = new HashSet<Child>();
// ...
}
@Entity
public class Child {
// ...
@ManyToOne(fetch = FetchType.LAZY)
private Parent parent;
// ...
}FetchType określa czy w przypadku pobrania jednej z tabel mamy odpytywać bazę danych o obiekt z nią połączony, jeżeli tak wybieramy FetchType.EAGER jeżeli nie i zapytanie ma być wykonane tylko gdy będziemy odwoływać się do konkretnej wartości należy wybrać FetchType.LAZY.
Zależności ManyToMany
Cel: Niech jeden obiekt posiada dołączenie nie do jednego a do wielu obiektów na raz (w obu kierunkach - czyli manager ma wielu podwładnych ale podwładni mogą mieć też wielu managerów).
Zadanie 9
Dodaj każdemu pracownikowi listę pracowników jemu podległych (może być pusta).
Dodaj w Pracowniku:
@ManyToMany(mappedBy = "subworkers", cascade = CascadeType.ALL)
private List<Employee> managers = new ArrayList<Employee>();
@ManyToMany(cascade = CascadeType.ALL)
private List<Employee> subworkers = new ArrayList<>();Zauważ, że lista jest obiektem, więc żeby nie była null musimy ją zainicjalizować. Zobacz w bazie danych jakie zależności powstały (powinna powstać nowa baza łącząca obie tabele - w naszym przypadku łącząca employee z employee).
Możemy także sami zdefiniować jak ma wyglądać tabela łączącą dwie tabele za pomocą adnotacji @JoinTable
@JoinTable(name="joinTwoTables",
joinColumns={@JoinColumn(name="id")},
inverseJoinColumns={@JoinColumn(name="id")})Stronnicowanie
Cel : Zdefiniuj query które zwracają stronicowane dane.
Często zdarza się, że mając wiele rekordów nie chcemy za każdym razem pobierać wszystkich z bazy danych ale chcielibyśmy podzielić je na mniejsze fragmenty (strony).
Najprostsza metoda oprogramowania stronicowania to konfiguracja zapytania query
Query query = entityManager.createQuery("From EMPLOYEE");
int pageNumber = 1;
int pageSize = 10;
query.setFirstResult((pageNumber-1) * pageSize);
query.setMaxResults(pageSize);
List <Foo> empList = query.getResultList();Wykorzystujemy metody:
setFirstResult(int): ustawia pozycje od której chcemy pobierać danesetMaxResults(int): ustawia liczbę rekordów, które chcemy pobrać z bazy danych
Przydatna jest też wiedza na temat liczby stron na którą dzielą się dane
Query queryTotal = entityManager.createQuery ("Select count(e.id) from EMPLOYEE e");
long countResult = (long)queryTotal.getSingleResult();
int pageSize = 10;
int pageNumber = (int) ((countResult / pageSize) + 1);Zadanie 10
Dodaj do kodu zapytanie pobierające wszystkich pracowników z podziałem na strony.
public List<Employee> getAllEmployeeByPage(int pagenr) {
//calculate total number
Query queryTotal = entityManager.createQuery
("Select count(e) from Employee e");
long countResult = (long)queryTotal.getSingleResult();
//create query
Query query = entityManager.createQuery("Select e FROM Employee e");
//set pageSize
int pageSize = 10;
//calculate number of pages
int pageNumber = (int) ((countResult / pageSize) + 1);
if (pagenr > pageNumber) pagenr = pageNumber;
query.setFirstResult((pagenr-1) * pageSize);
query.setMaxResults(pageSize);
return query.getResultList();
}Stwórz wielu pracowników za pomocą
for (int i = 1; i < 100; i++) {
entityManager.persist(Employee.copyEmployee(emp));
}Wywołaj kod w głównej klasie.
Extra
For IntelliJ Ultimate users
- *
Wykorzystano materiały z:
https://kobietydokodu.pl/13-2-baza-danych-z-jpa-cz-2/
http://math.uni.lodz.pl/~kowalcr/Bazy/Temat8.pdf
https://docs.jboss.org/hibernate/orm/3.6/quickstart/en-US/html/index.html
http://www.baeldung.com/hibernate-save-persist-update-merge-saveorupdate
http://www.mkyong.com/hibernate/hibernate-one-to-one-relationship-example-annotation/