Pracownia Programowania
REST API + SPRING FRAMEWORK
Uwaga! cały kod znajduje się na gałęzi SpringStart w repozytorium https://github.com/WitMar/PRA2021-PRA2022 . Kod końcowy w gałęzi SpringEnd.
Jeżeli nie widzisz odpowiednich gałęzi na GitHubie wykonaj Ctr+T, a jak to nie pomoże to wybierz z menu VCS->Git->Fetch.
API to skrót od Application Programming Interface; opisuje jak poszczególne elementy lub warstwy oprogramowania powinny się komunikować. W praktyce to najczęściej biblioteka oferująca metody, które umożliwiają realizację określonych operacji.
REST jest zbiorem reguł specyficznego sposobu wymiany komunikatów między serwerem a klientem. REST zaprojektowano tak, by był możliwie najprostszy. Restowe API jest blisko związany z protokołem sieciowym HTTP i wykorzystuje jego metody takie jak POST, GET, PUT, DELETE.
Kiedy tworzysz aplikację sieciową i chcesz udostępnić innym programistom możliwość integracji z nią, najlepiej udostępnić dobre API restowe wraz z dokumentacją.
HTTP
HTTP (Hyper Transfer Protocol) jest protokołem odpowiedzialnym za przesyłanie w Internecie stron WWW.
W zapytaniach HTTP możemy wyróżnić dwa elementy: nagłówek i ciało.
Nagłówek
Nagłówki HTTP spotkamy zarówno w zapytaniach, jak i w odpowiedziach. Są one pierwszymy liniami, oddzielone od ciała jedną pustą linią. Nagłówki są opcjonalne – protokół nie wymaga ich obecności. Nagłówki to pewnego rodzaju metadane i polecenia wymieniane przez przeglądarkę i serwer – mogą się w nich znaleźć informacje takie jak rodzaj przesyłanych treści (np. czy jest to obrazek czy plik JSON), sugestia dotycząca traktowania zawartości (czy przeglądarka ma wyświetlić daną treść, czy np. potraktować to jako pobieranie), jaki jest rozmiar przesyłanych danych, kiedy były modyfikowane, jakiego rodzaju odpowiedzi druga strona się spodziewa itp.
Nagłówki przyjmują postać klucz-wartość, zapisywane w postaci:
Klucz: wartość
Przykłady:
Nagłówek |
Opis |
Przykład |
Content-Type |
W zapytaniu oraz odpowiedzi określa, jakiego typu dane są przesyłane |
Content-Type: application/json |
Content-Length |
W zapytaniu oraz odpowiedzi zawiera informacje ile danych jest przesyłanych |
Content-Length: 20 |
Cookie |
W zapytaniu przesyłać zawartość Cookies przechowywanych dla danej,witryny. Może przechowywać wiele wartości w postaci klucz=wartość, pary,oddzielane są od siebie średnikami. |
Cookie: AcceptedCookiePolicy=1; Country=Poland; |
Set-Cookie |
W odpowiedzi jest to polecenie serwera, aby przeglądarka ustawiła,wartości Cookie; podobnie jak nagłówek Cookie może zawierać wiele par,postaci klucz=wartość oddzielonych średnikami |
Set-Cookie: UserID=JanNowak; SeenTutorial=1 |
Location |
W odpowiedzi serwer może poinformować, kiedy nastąpiła ostatnia zmiana,zawartości. Format daty jest specyficzny dla protokołu HTTP i określony w,dokumencie RCF 7231 |
Last-Modified: Tue, 15 May 2015 12:45:26 GMT |
Accept |
W zapytaniu klient może poinformować serwer, jakiego typu odpowiedzi,akceptuje. Dzięki temu serwer może zadecydować o wysłaniu odpowiedzi np.,w XML a nie JSON, co ma zastosowanie w wielu API |
Accept: application/xml |
Ciało
Ciało wiadomości przechowuje rzeczywiste dane żądania HTTP (takie jak dane formularza, etc.) i dane odpowiedzi HTTP z serwera ( pliki, obrazki, JSON, etc.).
Jeśli komunikat HTTP zawiera treść, to w wiadomości znajdują się zazwyczaj dane opisane w nagłówku. W szczególności
Content-Type: nagłówek dostarcza typ danych MIME w wiadomości takich jak text/html lub image/gif.Content-Length: nagłówek podaje liczbę bajtów w treści.
Parametry
Istnieją dwie podstawowe metody przekazania parametrów:
jako element URL podczas użycia metody GETjako para klucz:wartość nagłówka podczas użycia metody POST/PUT/DELETE
Parametry przekazywane metodą GET umieszczane są w adresie strony po znaku ? i rozdzielone znakiem &. Parametry są zwykle przekazywane w postaci par nazwa=wartość.
Przykład:
Status odpowiedzi
Jednym z elementów protokołu HTTP są kody odpowiedzi, zwanymi też statusami. To numeryczne, trzycyfrowe kody, które są dołączane do odpowiedzi i sygnalizują status odpowiedzi.
Nagłówki grupują się względem pierwszej cyfry w sekcje:
1xx – informacyjne, nieczęsto można spotkać, dotyczą bardziej środowiska niż samej aplikacji (np. 111 – serwer odrzucił połaczenie)2xx – zapytanie się powiodło3xx – przekierowanie, zapytanie należy kierować pod inny adres / serwer4xx – błąd aplikacji spowodowany działaniem użytkownika (np. wspomniany 404 – nie znaleziono – czy 403 – brak dostępu lub 400 – niepoprawnie zapytanie)5xx – błąd serwera (np. nieobsłużony wyjątek w Javie)
Najczęstszymi statusami HTTP, z którymi możemy się spotkać są:
200 - OK, 201 - Created, 202 - Accepted400 – Złe zapytanie (Brakuje w zapytaniu wymaganych parametrów lub nie może być poprawnie odczytane)401 – Nie powiodła się autentykacja, brak pozwolenia403 – Dostęp zabroniony404 – Nie znaleziono405 – Niedozwolona metoda (Np. wysłanie pod dany adres metody POST, a nie GET)500 – Błąd serwera503 – Serwis niedostępny
Lista wszystkich nagłówków HTTP dostępna jest tutaj:
Metody
Porównamy metody HTTP z typowymi operacjami CRUD (create, read, update, delete):
* metoda POST jest używana do tworzenia nowych rzeczy, to praktycznie odpowiednik Create z terminologii CRUD;* GET stanowi proste zapytanie z parametrami (odpowiednik Read);* metoda PUT aktualizuje lub zamienia dane, można ją traktować jako update/replace into z SQL lub Update z CRUD;* nazwa metody DELETE mówi sama za siebie i jest oczywiście odpowiednikiem Delete z CRUD.
Metoda |
Request body |
Response body |
Zastosowanie / opis |
GET |
niedozwolone |
opcjonalnie |
Pobieranie zasobu lub jego wyświetlenie, np. wyświetlenie formularza lub,strony. Parametry można przekazywac jedynie poprzez adres (np.,?nazwa=wartosc&nazwa2=wartosc2) |
POST |
opcjonalnie |
opcjonalnie |
Przesłanie danych zapisanych jako pary klucz-wartość do serwera (np.,wysłanie formularza, gdzie kluczem jest nazwa danego pola a wartością,wpisana przez nas wartość). Metoda ta pozwala przesyłać także pliki (a,także wiele pliki oraz pary klucz-wartość jednocześnie). |
PUT |
opcjonalnie |
opcjonalnie |
Przesyłanie ‚paczki’ danych, np. jednego pliku. Metoda ta ma pewne,ograniczenia, np. nie ma możliwości łaczenia par klucz-wartość z inną, przesyłaną treścią (np. plikiem). Obecnie używana głównie w przypadku, RESTowych serwisów, gdzie ciałem jest np. formularz zapisany w postaci,JSONa. |
DELETE |
opcjonalnie |
opcjonalnie |
Usuwanie zasobu na serwerze, z racji bezpieczeństwa praktycznie zawsze,jest wyłaczona domyślnie. Obecnie używana głównie w przypadku RESTowych,serwisów, wskazując, że dany zasób ma być usunięty. |
Protokół HTTP jest bezstanowy, tzn nie ‚przechowuje’ informacji o tym, co działo się wcześniej. Jest to oczywisty problem w większości przypadków, kiedy korzystamy z narzędzi wymagających zalogowania się – informacja o tym, jaki użytkownik jest zalogowany musi być przechowywana w jakiś sposób.
Rozwiązaniem stosowanym obecnie na szeroka skalę są tzw. ciasteczka – pierwotnie mające postać plików tekstowych w formacie klucz=wartość, obecnie przechowywane w wewnętrznej bazie danych przeglądarki.
REST
REST oznacza głównie komunikację przez HTTP z użyciem kilku metod tegoż HTTP i wymianę danych w formacie JSON lub XML.
Najważniejszą własnością RESTa są zasoby. Każdy zasób ma swój adres. Adres jest unikalny i zawsze ten sam. Nie może być dwóch zasobów pod tym samym adresem. Jeden zasób nie powinien też pojawiać się pod kilkoma adresami. Przykład /samochod.
Przykład:
URL |
POST |
PUT |
GET |
DELETE |
/samochod |
Stwórz nowy samochód |
Zamień/aktualizuj wszystkie samochody |
Pobierz wszystkie samochody |
Usuń wszystkie samochody |
/samochod/{id} |
Stwórz samochód o danym id |
Aktualizuj samochód o danym id |
Pobierz samochów o danym id |
Usuń samochód o danym id |
Wprawdzie REST nie wymusza użycia HTTP, ale prawie zawsze idzie z nim w parze. HTTP to coś więcej niż znane wszystkim GET i POST. Mamy nagłówki żądania i odpowiedzi, mamy kody odpowiedzi, mamy też kilka różnych metod wywołania. REST stara się wykorzystać wszystkie te możliwości do maksimum.
Uwagi:
* POST jest z kilku względów wyjątkową metodą HTTP z punktu widzenia REST. Najpopularniejsze jej zastosowanie to dodanie zasobu do kolekcji. Co ważne, identyfikator takim zasobom nadaje serwer, a co za tym idzie, klient musi mieć możliwość przenawigowania do dodanego przez siebie zasobu. Dlatego jeśli żądanie przejdzie poprawnie walidację i zasób zostaje utworzony, to serwer musi zwrócić kod 201 / Created wraz z adresem URI nowo utworzonego zasobu zamieszczonym w nagłówku Location.* PUT służy także do dodawania zasobów. Różnica polega na tym, że żądanie PUT musi być idempotentne. Operacje idempotentne (w algebrze) to takie, które wielokrotnie stosowane nie zmienią wyniku. Zatem jedyną możliwość idempotentnego dodania zasobu jest wstawienie go pod Id nadany przez klienta. Każdy kolejny, taki sam request będzie traktowany jako aktualizacja zasobu znajdującego się pod wskazanym Id.Konsekwencja jest taka, że jeżeli metodę PUT wywołamy 100 razy z takimi samymi nagłówkami i body, to w bazie danych będzie cały czas jeden zasób, natomiast w przypadku dodawania przez POST utworzyć się powinno 100 zasobów z różnymi Id.* W przypadku chęci wywołania metody GET z parametrem złożonym, który nie może być zapisany w URL, stosujemy metodę POST jako jej zamiennik.
Postman
Postman został stworzony do wsparcia wszystkich aspektów rozwoju API. Postman jest aplikacją, która pozwala na przesyłanie requestów i odbieranie odpowiedzi od serwisów internetowych.
Jak zainstalować Postmana?
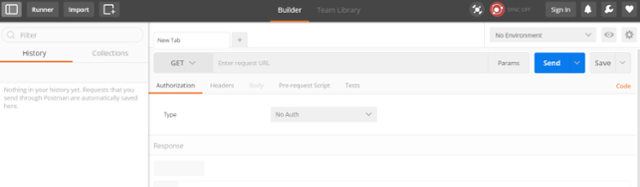
Po lewej stronie mamy historię wykorzystywanych zapytań, po prawej wprowadzamy szczegóły zapytania. W dolnej części pokazywana jest odpowiedź od serwera.
Metoda GET służy do pobierania danych. W polu obok (URL) wpisujemy adres metody, do której się odwołujemy.
Zadanie
Uruchom serwer korzystając z kodu na branchu SpringBootEnd kodem aplikacji będziemy zajmować się na kolejnych zajęciach) z repozytorium
Utworzony serwis zapisuje dane o produktach (product). Serwis korzysta z bazy danych HSQL (przechowywanej w pamięci) więc każde uruchomienie serwisu tworzy nową bazę danych w pamięci.
Zadanie
Uruchom klasę SprinApp.
Sprawdź czy aplikacja działa wchodząc na managera aplikacji, oraz na
Powinieneś zobaczyć stronę ze słowem "index" (ale nie błąd 404 HTTP). W każdym kroku w terminalu Intellij możesz sprawdzić czy nie występują jakieś błędy.
Zadanie
Otwórz Postmana
Nasz serwis posiada metodę do generowania danych.
Spróbuj wejśc przeglądarką na adres:
Przeglądarka wysyła zapytanie typu GET do serwisu, powinieneś zobaczyć błąd. Porównaj wynik z wynikiem zapytania w Postmanie. Wpisz adres w oknie adresu w Postmanie wybierz metodę GET. Wciśnij Send.
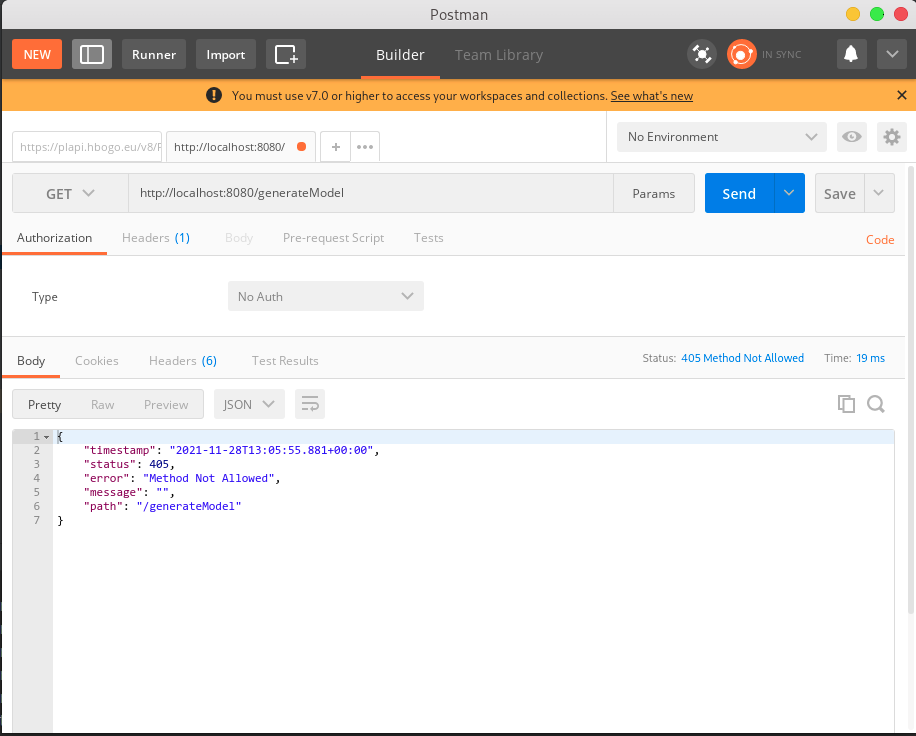
Jak widzimy żądanie nie jest "znane" a to dlatego, że zaprogramowaliśmy nasz skrypt tak by uruchamiał się poprzez wykonanie zapytania typu POST.
Zadanie
Skrypt do generowania danych wywoływany jest poprzez zapytanie POST. Zmień typ zapytania z GET na POST.
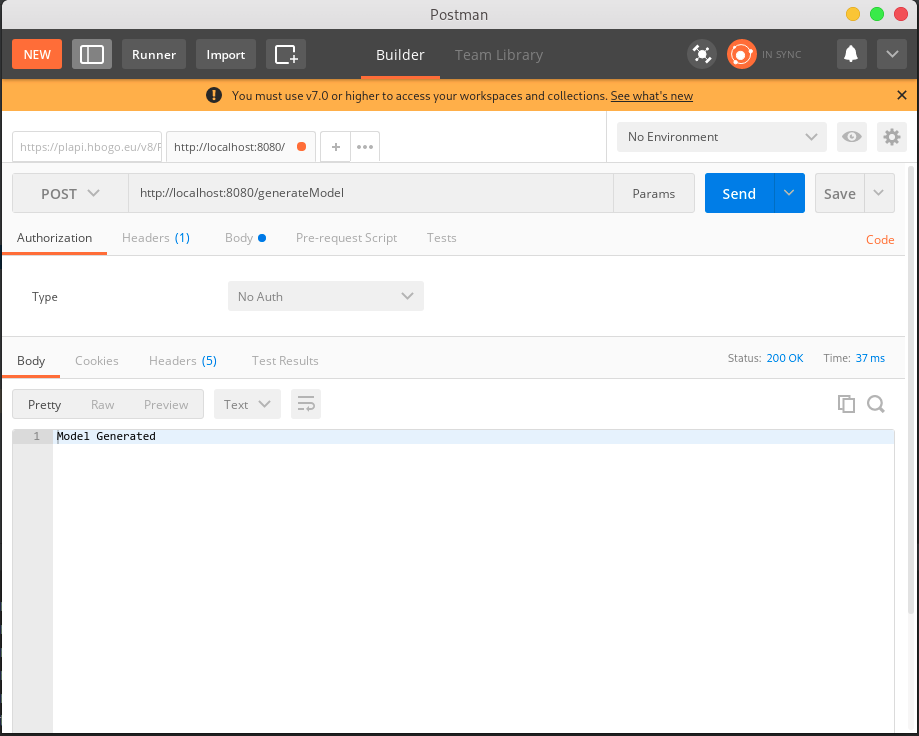
Zadanie
Wywołaj zapytanie GET na scieżce /api/products aby odczytać wszystkie produkty
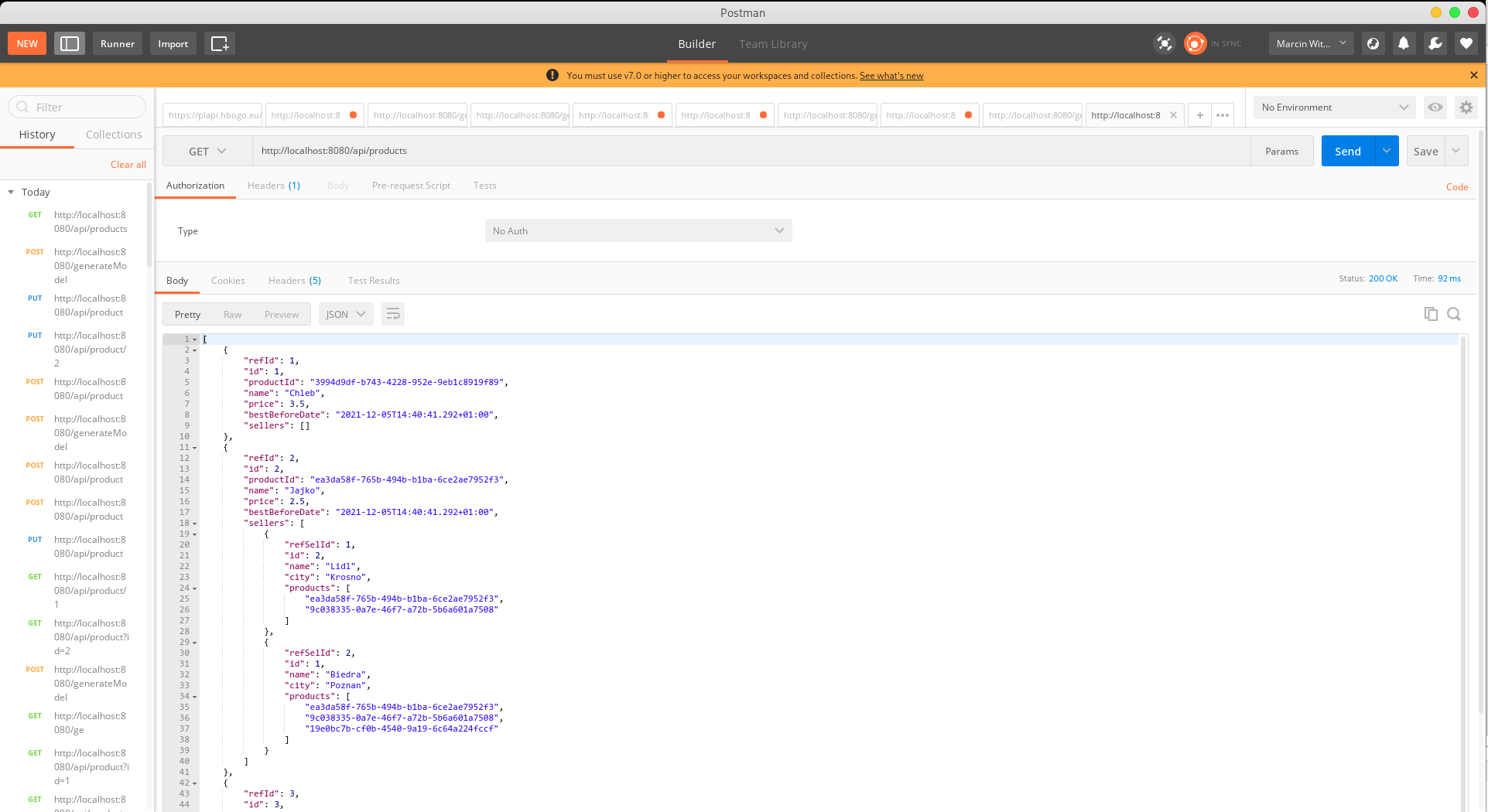
Jeżeli nie widzisz produktów najprawdopodobniej nie wywołałeś metody generateModel (musisz to robić także po każdym restarcie serwera). Spróbuj powtórzyć kroki powyżej.
Zadanie
Podejrzyj konretny pojedynczy produkt poprzez podanie URL w ścieżce /api/product/1 oraz /api/product poprzez podanie parametru (Params) id równego 1. Zobacz co stanie się gdy podasz złe parametry.
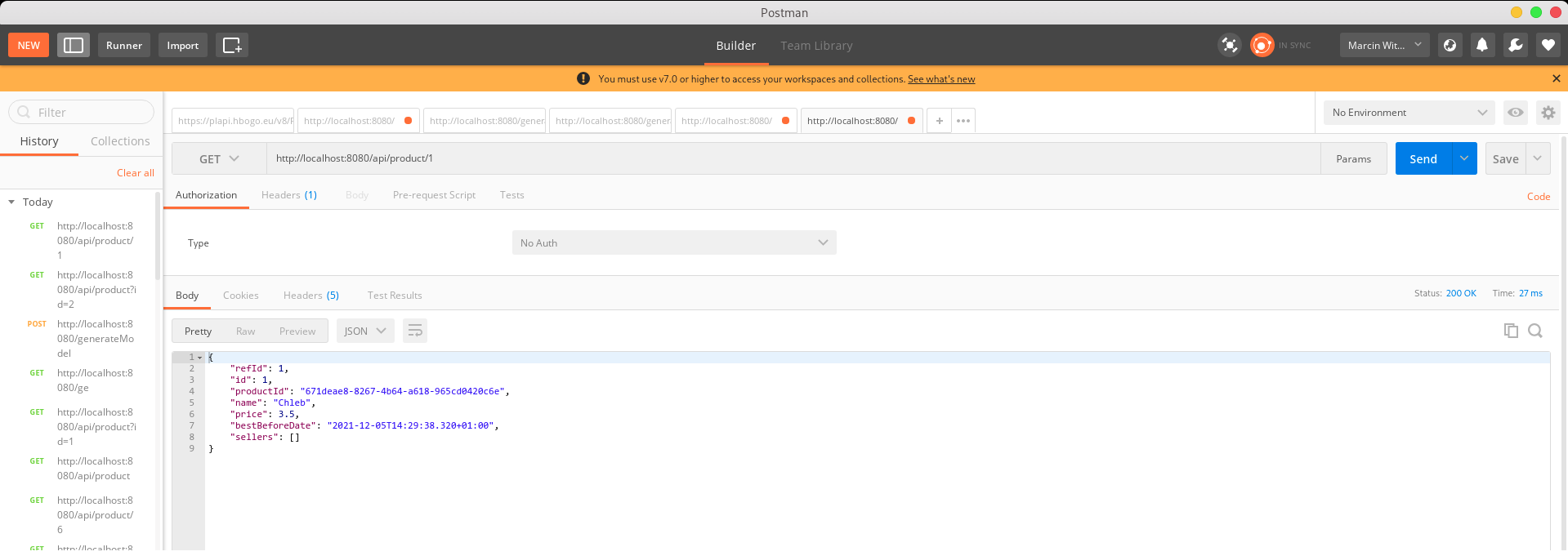
Okienko do wpisywania parametrów pojawi się po wybraniu Params. Zwróć uwagę na postać linka w drugim przypadki (parametr sam dodaje się do linka).
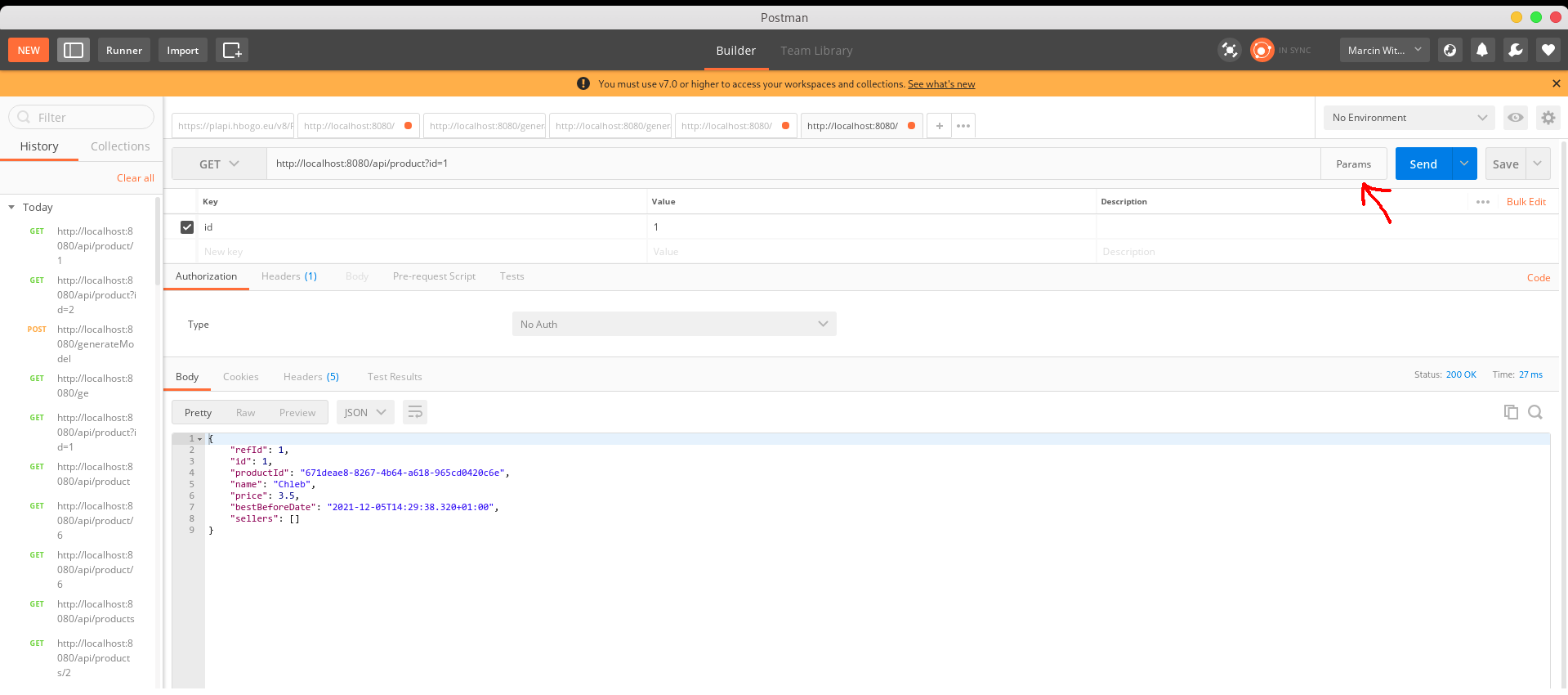
Zadanie
Dodaj produkt wywołaniem metodu post na /api/product przekazując w body JSON'a. Element dodajemy jako body zapytania http. Zmień przy tym typ przekazywanych danych na JSON. W odpowiedzi powinieneś uzyskać zdeserializowany obiekt. Zobacz jakie Id otrzymał dodany obiekt.
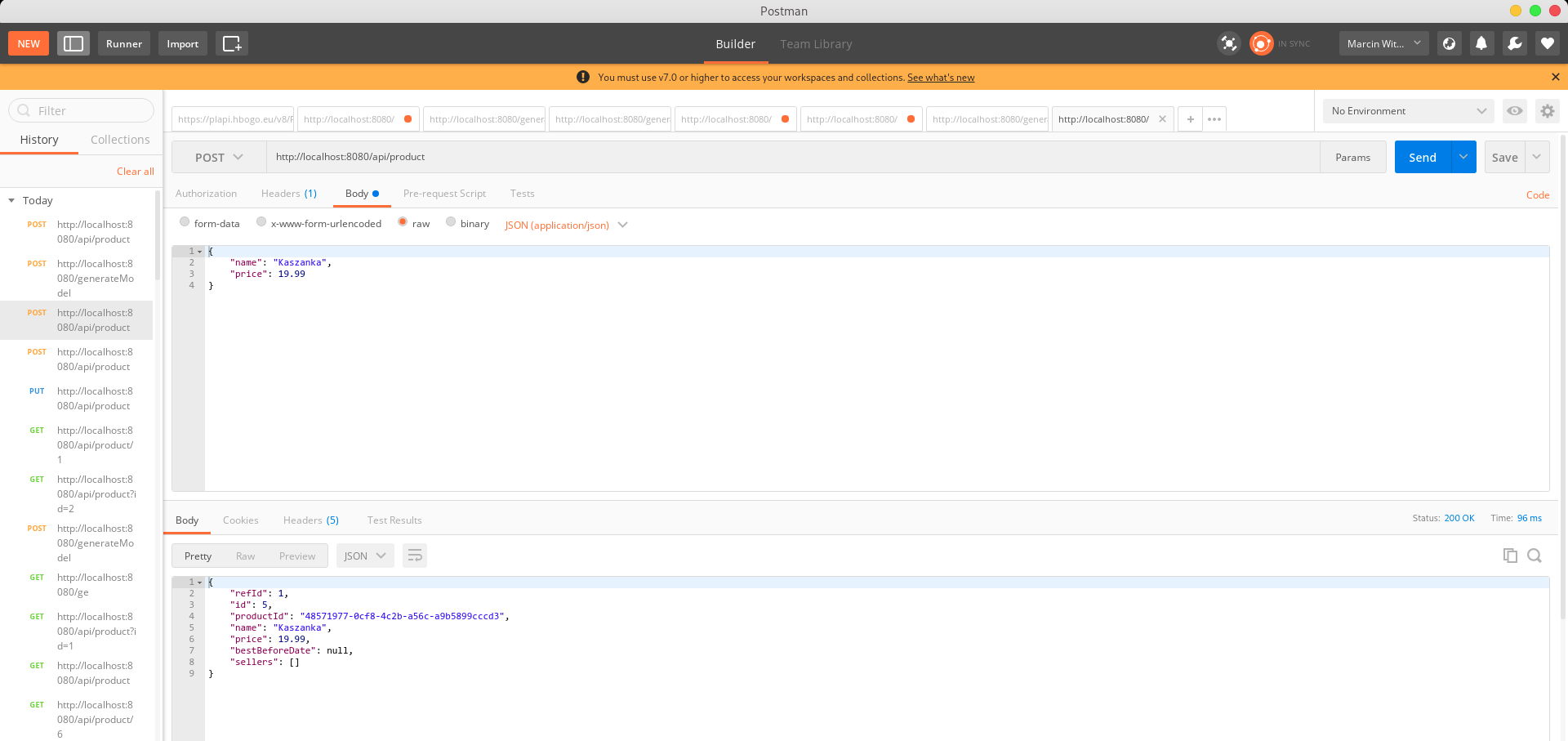
Zadanie
Wykonaj zapytanie PUT na /api/product, przekazując w Body JSON'a aby wyedytować Jajko na Jajko Eko i zmienić mu cenę na 22.5. Nasz endpoint oczekuje w tym wypadku całeo obiektu wraz z Id.
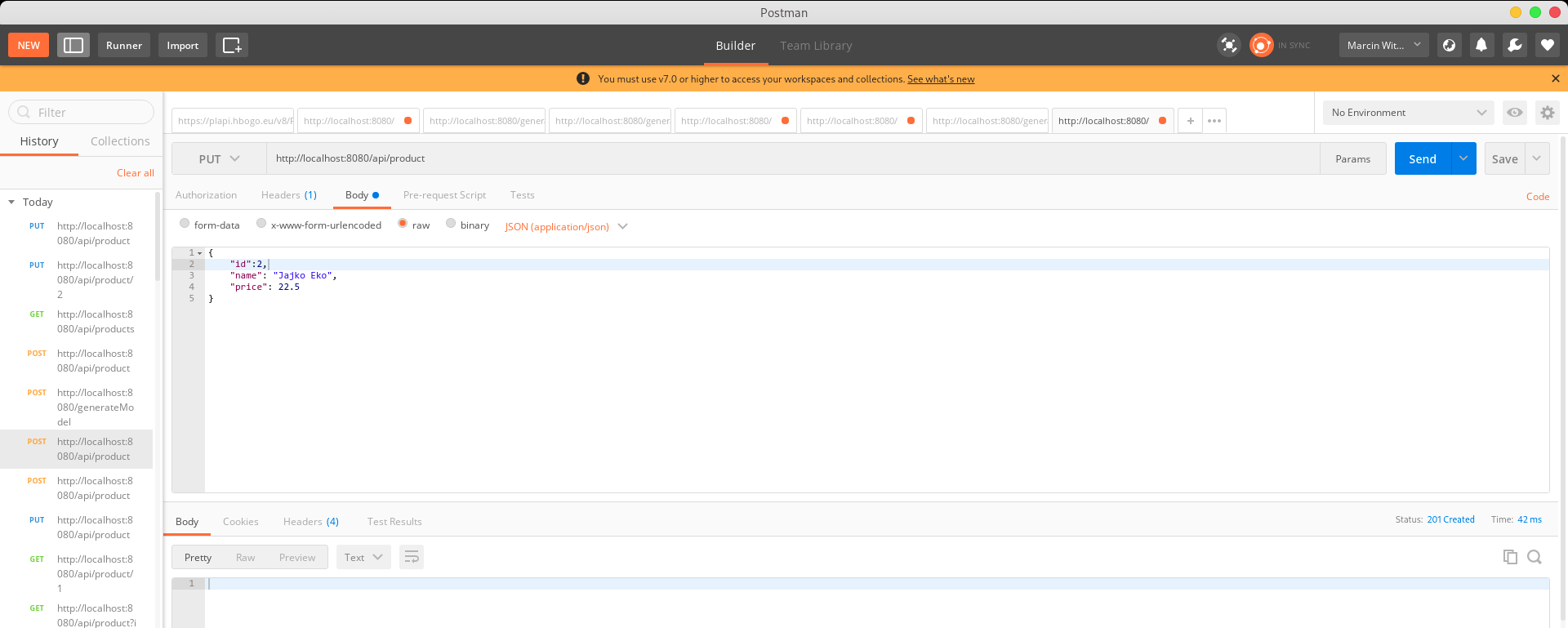
Sprawdź na liście wszystkich produktów (GET na api/products), czy się powiodło. Zauważ, że PUT wyedytował cały obiekt, co spowodowało że elementy nie przypisane przez nas zostały wyczyszyczone.
Zadanie
Wykonaj zapytanie DELETE na /api/product/1.
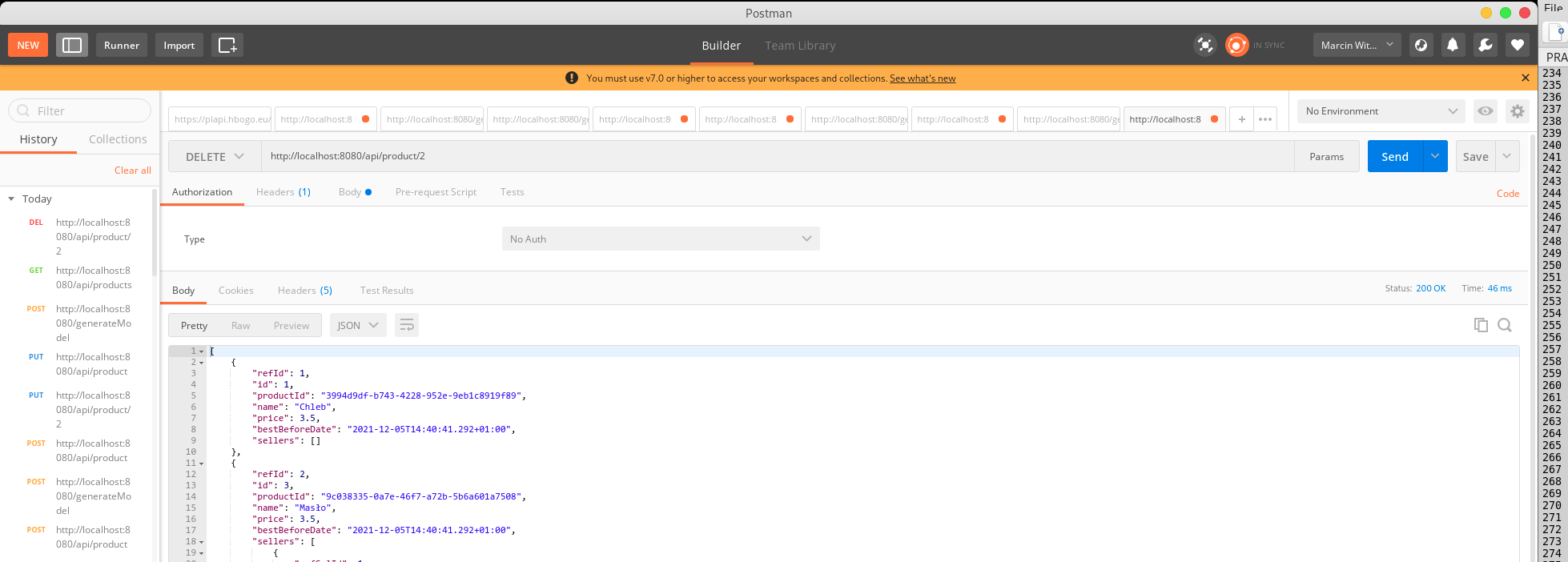
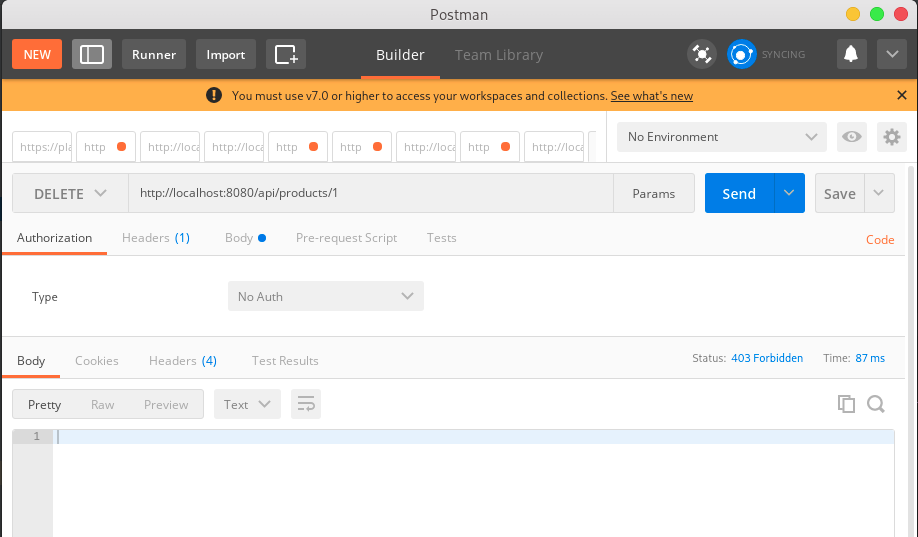
Wykonaj zapytanie DELETE na /api/products/1 by zobaczyć jak wygląda błąd. W tym wypadku nasza aplikacja zwróci bład HTTP forbidden i puste body.
Swagger
Swagger 2 is an open-source project used to describe and document RESTful APIs.
Swagger jest biblioteką służącą do automatycznego generowania dokumentacji. Udostępnia bardzo proste i klarowny opis naszego API dla innych developerów, generuje się automatycznie z naszego kodu (oczywiście po dodaniu biblioteki do naszej aplikacji) oraz umożliwia testowanie naszych endpointów.
Wejdź na:
I powtórz wyżej wymienione kroki korzystając ze swager api.
HTTP calls in Java
Możemy również (w celu testowania lub dowolnym innym) wykonywać żądania HTTP z kodu. Dla uproszczenia użyjemy biblioteki Apache.httpclient.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>Our get method looks as follows:
HttpGet request = new HttpGet("http://localhost:8080/api/products/");
// add request headers
request.addHeader("custom-key", "programming");
try (CloseableHttpResponse response = httpClient.execute(request)) {
// Get HttpResponse Status
System.out.println(response.getStatusLine().toString());
HttpEntity entity = response.getEntity();
Header headers = entity.getContentType();
System.out.println(headers);
if (entity != null) {
// return it as a String
String result = EntityUtils.toString(entity);
System.out.println(result);
}
}Our post method looks as follows:
HttpPost post = new HttpPost("http://localhost:8080/api/product/");
String json = "{\"name\": \"Kaszanka\",\n" +
" \"price\": 12.5,\n" +
" \"bestBeforeDate\": \"2020-12-19T11:07:49.589Z\"}";
StringEntity entity = new StringEntity(json);
post.setEntity(entity);
post.setHeader("Accept", "application/json");
post.setHeader("Content-type", "application/json");
try (CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = httpClient.execute(post)) {
HttpEntity rEntity = response.getEntity();
if (rEntity != null) {
// return it as a String
String result = EntityUtils.toString(rEntity);
System.out.println(result);
}
}Spring
Spring jest Frameworkiem aplikacji pozwalającym na tworzenie aplikacji w języku Java w oparciu o paradygmat odwrócenie sterowania (ang. Inversion of Control, IoC).
Odwrócenie sterowania pozwala na modyfikację zachowania (ustawień) programu w czasie uruchomienia, na co nie pozwala tradycyjne podejście. Contener aplikacji (framework) jest odpowiedzialny za zarządzanie cyklem życia obiektów: tworzenie, inicjalizację, konfigurację i zarządzanie zależnościami między obiektami.
Obiekty stworzone przez kontener nazywane są obiektami zarządzanymi lub beanami. Ustawienia frameworka Spring mogą być zdefiniowane w pliku properties,XML (Extensible Markup Language), YAML lub za pomocą adnotacji w kodzie. W naszym przypadku skupimy się na mechanizmie adnotacji i pliku YAML.
Obiekty są przekazywane do klas poprzez mechanizm dependency lookup lub dependency injection. Dependency lookup polega na tym, że program zgłasza się do kontenera z prośbą o udostępnienie zadanego zasobu (na podstawie nazwy lub typu). Dependency injection polega na tym, że kontener automatycznie wstrzykuje implementację obiektu do innego obiektu poprzez konstruktor, pole lub metodę.
Konfiguracja plik properties
Domyślnie Spring Boot ma dostęp do konfiguracji ustawionych w pliku application.properties, który używa formatu klucz-wartość:
#---
spring.datasource.url=jdbc:h2:dev
spring.datasource.username=SA
spring.datasource.password=passwordW plikach tego typu każda linia jest pojedynczą konfiguracją, więc w przypadku danych hierarchicznych, zmuszeni jesteśmy do korzystania z tych samych przedrostków w każdej linii. W tym powyższym przykładzie każdy klucz należy do sekcji spring.datasource.
W ramach naszych wartości możemy używać symboli ze składnią ${}, aby odnosić się do zawartości innych kluczy, właściwości systemu lub zmiennych środowiskowych:
app.name=MyApp
app.description=${app.name} is a Spring Boot applicationKonfiuracja plik Yaml
Yaml to specjalny format zapisu danych strukturalnych, podobny w logice do formatu json. Poszczególne elementy struktury danych są oddzielane znakami nowej linii, a ich hierarchia ustalana jest na podstawie wcięcia linii. Język wprowadza trzy podstawowe struktury danych, które mogą być wkomponowane w dokument: listy, słowniki i typy proste. Obsługuje również referencje, które eliminują konieczność redundancji danych.
Przykład:
---
tekst: "pierwsze zdanie"
drugi: "drugie zdanie"
pi: 3.14159
boże-narodzenie: true
jajka: 3
ptaki:
- czyżyk
- kos
- gołąb
- wróbel
swieta:
barszcz: litr
pierniczki: 3
czekoladki: null
prezenty:
zabawki: 1
schowek: "pod choinką"
światełka: dwaPlik zaczyna się od trzech myślników. Te myślniki wskazują początek nowego dokumentu YAML. YAML pozwala, podobnie jak properties na definiowanie wielu konfiuracji w obrębie jednego pliku (elementy po trzech myślinikach są traktowane tak jakby były zapisane w osobnym pliku). Następnie widzimy konstrukcję, która tworzy większość typowego dokumentu YAML: parę klucz-wartość. Tekst to klucz, który wskazuje na wartość typu string: "pierwsze zdanie". YAML obsługuje więcej niż tylko Stringi. Plik zaczyna się od sześciu par klucz-wartość. Mają cztery różne typy danych. Tekst i drugi to Stringi. Pi to liczba zmiennoprzecinkowa. boże-narodzenie to wartość logiczna. Jajka to liczba całkowita. Siódmy element to tablica. Lista ptaki ma cztery elementy, każdy oznaczony kreską otwierającą. Elementy w liście poprzedzone są wcięciem. Wcięcie to sposób, w jaki YAML oznacza zagnieżdżanie. Liczba spacji może się różnić w zależności od pliku, ale tabulatory nie są dozwolone. Obiekt swieta, zawiera pięć elementów, z których każdy ma wcięcie. Możemy traktować swieta jako słownik, który zawiera dwa ciągi znaków, dwie liczby całkowite i inny słownik. YAML obsługuje zagnieżdżanie par klucz-wartość i mieszanie typów. Ciągi znaków nie otoczone cudzysłowem są rozpoznawane jako stringi lib liczby w zależności od ich postaci.
Przykład spring:
spring:
datasource:
password: password
url: jdbc:h2:dev
username: SAW ramach naszych wartości możemy używać symboli ze składnią ${}, aby odnosić się do zawartości innych kluczy, właściwości systemu lub zmiennych środowiskowych:
Przykład spring:
variable: ${PATH}
name: test-YAML
environment: testing
enabled: false
servers: www.abc.test.com, www.xyz.test.comUwaga! Spring nie radzi sobie dobrze z listami obiektów w Yaml oznaczanych myślnikami, dlatego stosujemy notacje z przecinkami.
Import wartości zmiennej w kodzie programu dla zmiennych zdefiniowanych w pliku Yaml:
@Value("${variable}")
private String variable;
@Value("${name}")
private String name;
@Value("${environment}")
private String environment;
@Value("${enabled}")
private boolean enabled;
@Value("${servers}")
String[] servers;Inversion of Control
Paradygmat (czasami rozważany też jako wzorzec projektowy lub wzorzec architektury) polegający na przeniesieniu funkcji sterowania wykonywaniem programu do używanego frameworku. Framework w odpowiednich momentach wywołuje kod programu stworzony przez programistę w ramach implementacji danej aplikacji. Odbiega to od popularnej metody programowania, gdzie programista tworzy kod aplikacji, który steruje jej zachowaniem. Następnie używa we własnym modelu sterowania bibliotek dostarczonych przez framework.
Zaletami tego podejścia są:
rozdział implementacji metod od implementacji konkretnych interfejsówłatwość w podmianie implementacji danych klaswiększa modułowość programuwiększa łatwość w testowaniu programu poprzez rozdzielenie komponentów i możliwość mockowania zależności
Dependency injection
Wstrzykiwanie zależności (ang. Dependency Injection, DI) – wzorzec projektowy i wzorzec architektury oprogramowania polegający na usuwaniu bezpośrednich zależności pomiędzy komponentami na rzecz architektury typu plug-in. Polega na przekazywaniu gotowych, utworzonych instancji obiektów udostępniających swoje metody i właściwości obiektom, które z nich korzystają (np. jako parametry konstruktora). Stanowi alternatywę do podejścia, gdzie obiekty tworzą instancję obiektów, z których korzystają np. we własnym konstruktorze
Oto jak tworzyliśmy obiekty w tradycyjnym podejściu:
public class Store {
private Item item;
public Store() {
item = new ItemImplementation();
}
}W podanym wyżej przykładzie związujemy z obiektem Store szczególną implementację interfejsu Item.
W przypadku DI, możemy przekazać do obiektu Store dowolną implementację Item, poprzez sparametryzowanie tworzenie obiektu:
public class Store {
private Item item;
// Someone will do this part for us
public Store(Item item) {
this.item = item;
}
}Bean
Adnotacja na klasie: @Configuration wskazuje, że dana klasa służy Springowi jako klasa definiująca Beany w projekcie. Adnotacja @Bean nad metodą mówi że dana metoda zwraca obiekt, który ma być traktowany (zarejestrowany) jako Bean przez framework w kontekście Springa. Najprostszy przykład klasy z adnotacją @Configuration znajdziemy poniżej:
@SpringBootConfiguration
public class HelloWorldConfig {
@Bean
public HelloWorld helloWorld() {
return new HelloWorld();
}
}Domyślnie Beany są singletonami, jeżeli chciałbyś to zmienić i wymusić inny typ zachowania, spójrz na dokumentację
Autowired
W środowisku Spring kontener IoC jest reprezentowany przez interfejs ConfigurableApplicationContext. Kontener Spring jest odpowiedzialny za tworzenie instancji, konfigurowanie i składanie obiektów znanych jako beans, a także zarządzanie ich cyklem życia.
Aby zmontować komponenty bean, kontener używa metadanych konfiguracyjnych, które mogą mieć postać konfiguracji XML lub adnotacji. My będziemy używać adnotacji.
W przypadku DI dla pól klasy możemy wstrzyknąć zależności zaznaczając je adnotacją @Autowired:
@Autowired will tell Spring to search for a Spring bean which implements the required interface and place it automatically into the variable.
public class Store {
@Autowired
private Item item;
}Przy tworzeniu obiektu typu Store, nie wywołujemy konstruktora ani żadnych metod ustawiających wartość pola Item, kontener sam, korzystając z mechanizmu refleksji, wstrzyknie nam implementację beana Item do klasy Store.
Zadanie
Otwórz kod znajdujący się na branchu SpringStart. Zobacz jakie elementy można znaleźć w kodzie aplikacji.
Dodaj do projektu nową klasę Printer
import org.springframework.beans.factory.annotation.Autowired;
public class Printer {
@Autowired
private HelloWorld helloWorld;
public Printer() {
}
public void sendMessage() {
helloWorld.getMessage();
}
}Zadanie
Dodaj do konfiguracji wpis o Printer jako bean, oraz pobierz w głównej klasie jego implementację z kontekstu. Sprawdź, czy zmiany w ustawieniu helloWorld.setMessage() wpłyną na wynik wywołania metory print() obiektu typu Printer.
Component / Service
Dzięki adnotacjom @Component (i @Service) możemy oznaczać klasę Javovą jako bean, tak by mechanizm skanujący komponenty mógł ją pobrać i przenieść do kontekstu aplikacji.
Kontekst Springa musi wiedzieć, gdzie szukać Beanów, w przeciwnym razie ich nie znajdzie, dodać pobranie beana serwis do głównej klasy:
Service service = (Service) ctx.getBean(ServiceImpl.class);
service.print();Spróbuj uruchomić kod i zobacz co się stało.
Podczas tworzenia aplikacji Spring Boot, musisz powiedzieć Spring Framework, gdzie szukać komponentów Spring. Używanie funkcji @ComponentScan jest jednym z ustawień konfiguracji Springa. Domyślnie skanowanie komponentów mówi Springowi, aby przyjrzał się danemu pakietowi i jego wszystkim podpakietom (jeśli chcesz określić inny pakiet, musisz ustawić dodatkowo parametr w adnotacji).
Zadanie
Dodaj @ComponentScan do pliku konfiguracyjnego. Uruchom program ponownie.
Uwaga! Autowire działa tylko dla klas tworzonych przez Spring, jeżeli w kodzie zdecydujemy się utworzyć dany obiekt przez new(), to w odpowiednie pola nie zostaną wstrzyknięte implementacje beanów.
Wykorzystano materiały z:
https://www.itmagination.com/pl/booster/basic-testing-of-rest-api-using-postman
https://mickl.net/2016/10/10/8-rzeczy-ktore-warto-wiedziec-projektujac-rest-owe-api/
http://www.moseleians.co.uk/wp-content/uploads/cmdm/9632/1422444257_api-restowe-whitepaper.pdf
https://kobietydokodu.pl/niezbednik-juniora-protokol-http/
http://threats.pl/bezpieczenstwo-aplikacji-internetowych/absolutne-podstawy
http://adam.wroclaw.pl/2014/07/restful-api-jak-zrobic-je-dobrze/
https://github.com/callicoder/spring-boot-mysql-rest-api-tutorial
https://www.journaldev.com/2461/spring-ioc-bean-example-tutorial
https://www.baeldung.com/inversion-control-and-dependency-injection-in-spring
https://en.wikipedia.org/wiki/Spring_Framework
https://www.tutorialspoint.com/spring/spring_java_based_configuration.htm
https://www.cloudbees.com/blog/yaml-tutorial-everything-you-need-get-started