Pracownia Programowania
Uwaga! Kod do zajęć znajduje się na gałęzi StreamsAndCollectionsStart w repozytorium https://github.com/WitMar/PRO2023.git . Kod końcowy w gałęzi StreamsAndCollectionsEnd.
Jeżeli nie widzisz odpowiednich gałęzi na GitHubie wykonaj Ctr+T, a jak to nie pomoże to wybierz z menu Git->Fetch.
Fluent API
Termin "Fluent Interface" został wymyślony przez Martina Fowlera i Erica Evansa. Fluent API oznacza zbudowanie API w taki sposób, aby spełniało następujące kryteria:
* Programista może bardzo łatwo zrozumieć interfejs API.* Interfejs API może wykonać szereg działań na raz. W Javie możemy to zrobić za pomocą szeregu wywołań metod (łańcuchy metod).* Nazwa każdej metody powinna być związana z domeną, w której operuje.* Interfejs API powinien być wystarczająco sugestywny, tak by wskazać użytkownikom interfejsu API, co robić dalej i jakie możliwe operacje mogą podjąć użytkownicy w danym momencie.
Najczęstsze zastosowanie to tworzenie tzw. The Fluent Interface builder dobra praktyka mówi, żeby używać go, gdy konstruktor ma więcej niż cztery lub pięć parametrów, tworzymy wtedy specjalną klasę konstruktora, która pomaga w tworzeniu obiektów.
Główną ideą jest by zamiast:
Person(String name, Title title) {
this.name = name;
this.title = title;
}
Person adam = new Person("Adam Z.", Title.PROF);użyć łatwiejszej w analizie fasady otaczającej konstruktor w formie tzw. buildera:
public class PersonBuilderBuilder implements IPersonBuilder {
Title title;
String name;
public Person build() {
Person person = new Person(this.name, this.title);
return person;
}
@Override
public IPersonBuilder withName(String name) {
this.name = name;
return this;
}
@Override
public IPersonBuilder withTitle(Title title) {
this.title = title;
return this;
}
}
PersonBuilderBuilder personBuilder = new PersonBuilderBuilder();
Person person = personBuilder.withName("Marcin Witkowski")
.withTitle(Title.DR)
.build();Co znacznie ułatwia odczytanie i zrozumienie kodu.
W powyższym przykładzie używamy również interfejsów, które w ogólności nie są konieczne do stosowania (zadane metody możemy zaimplementować także bez występowania interfejsu), popatrz także na przykład:
Ten sam pomysł można zastosować nie tylko w przypadku budowy nowego obiektu, ale także do zarządzania obiektami i ich metodami.
Kluczowym elementem tej techniki jest to, że implementacja fluent API wymaga przekazania tego samego obiektu jako wyniku funkcji (return this).
Ponownie w przykładzie używamy interfejsu, który w ogólności nie jest konieczny:
public class Person implements IPerson {
List<Person> friends = new ArrayList<>();
String name;
Enum title;
@Override
public IPerson addFriend(Person friend) {
this.friends.add(friend);
return this;
}
}Aby dodać znajomego dla osoby, wykonujemy metodę addFriend(), która zwraca obiekt Person, który pozwala nam korzystać łańcuchowo z innych metod (podobnie działają potoki w systemach operacyjnych).
adam.addFriend(Ben).addFriend(Barrack).addFriend(John);Task 1: Builder
Przejdź do klasy MainFluentApi i stwórz obiekt klasy Person korzystając z Buildera. Sprawdź czy możesz stworzyć obiekt korzystając z konstruktora klasy poprzez operator new Person().
Task 2: Friends
Stwórz dwie inne osoby i dodaj je jako przyjaciół pierwszej z osób.
Task 3: Hello
Zaimplementuj metodę sayHelloToFriends w klasie Person tak by wypisywała ona na ekran "Hello <person name>". Sprawdź czy implementacja działa.
Function
Function to specjalny interfejs w javie do definiowania funkcji. Posiada on metody apply() . Wyróżniamy trzy rodzaje funkcji : Function (która przyjmuje i zwraca argumenty), Consumer (która przyjmuje arumenty, ale nic nie zwraca) oraz Producer (który produkuje dane, ale nie pobiera argumentów).
Function<Integer, Double> half = a -> a / 2.0;
// apply the function to get the result
System.out.println(half.apply(10));addThen() zwraca funkcje złożoną, gdzie funckja będąca argumentem zostanie wykonana po oryginalnej funkcji
Function<Integer, Double> half = a -> a / 2.0;
// Now treble the output of half function
half = half.andThen(a -> 3 * a);
// apply the function to get the result
System.out.println(half.apply(10));identity() - zwraca funkcję identycznościową (zwracającą na wyjście to co podamy na wejściu).
Function<Integer, Double> half = a -> a / 2.0;
// Now treble the output of halffunction
half = half.andThen(Function.identity());
// apply the function to get the result
System.out.println(half.apply(2));Jak można zauważyć w przykładach, do określenia funkcji używamy tzw. wyrażeń Lamba o notacji x -> f(x). Lewa strona strzałki oznacza argumenty (w tym przypadku pojedynczy argument), a prawa strona oznacza funkcję, która może skłądać się z jednej lub większej liczby instrukcji (w tym drugim przypadku należy użyć {}).
Task 4: Process
Zaimplementuj funkcje processFriends() w ten sposób by czyściła listę przyjaciół.
Task 5: Best friend
Zaimplementuj funkcję wyboru best friend tak by wybierała jako najlepszego przyjaciela pierwszy element listy przyjaciół. Sprawdź co stanie się gdy lista będzie pusta.
Kolekcje
Kolekcje w Java:
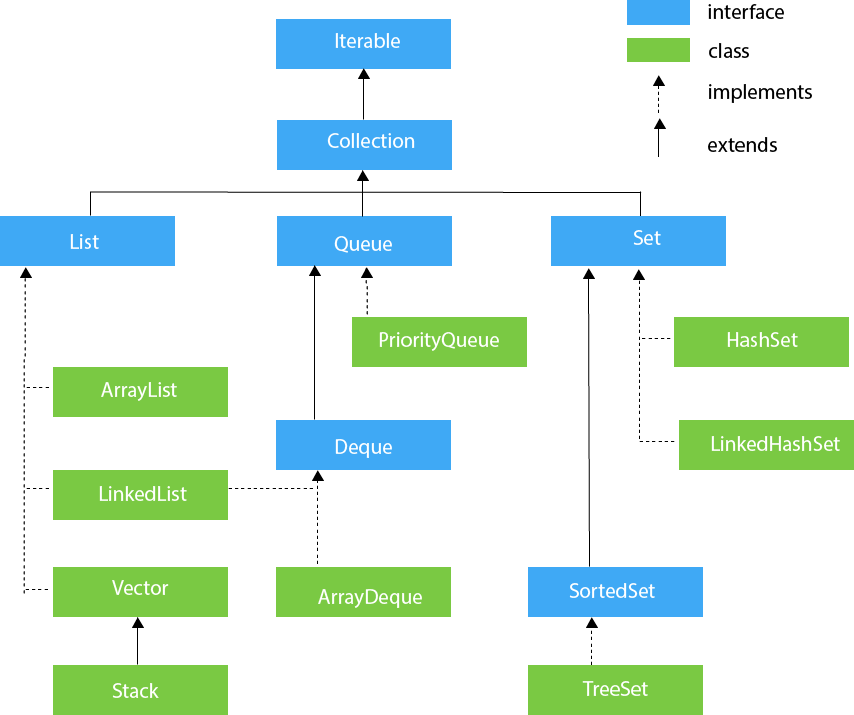

Przykłady:
List<Integer> list = new ArrayList<>();
Set<Integer> list = new HashSet<>();Interfejs mówi nam, że operujemy na obiekcie Listy ze wszystkimi jej możliwościami natomiast prawa strona mówi nam z jakiej implementacji będziemy korzystać (np. dla ArrayList wstawianie elementu na środku listy będzie szybkie, natomiast dla LinkedList wydajniejsza będzie operacja usuwania elementu z listy).
Mapy
Mapy to struktury danych opartych na relacji klucz-wartość, w niektórych językach struktura ta jest nazywana słownikiem. Najpopularniejszą implementacją Mapy jak HashMapa oparta na funkcji skrótu mapującej klucz na miejsce w pamięci.
HashMap nie daje żadnej gwarancji wzlędem kolejności elementów na mapie. Oznacza to, że nie możemy przyjąć żadnej kolejności podczas iteracji po kluczach czy wartościach hash mapy:
@Test
public void whenInsertObjectsHashMap_thenRandomOrder() {
Map<Integer, String> hashmap = new HashMap<>();
hashmap.put(3, "TreeMap");
hashmap.put(2, "vs");
hashmap.put(1, "HashMap");
assertThat(hashmap.keySet(), containsInAnyOrder(1, 2, 3));
}Elementy w TreeMap są sortowane zgodnie z ich naturalną kolejnością.
Strumienie
Tradycyjnie w Javie do przechodzenia po kolekcjach korzystaliśmy z jawnych iteratorów
List <String> names = new ArrayList <>();
for (Student student: students) {
if (student.getName ().startsWith("A")) {
names.add (student.getName ());
}
}Wykorzystując strumienie korzystamy z tzw. wewnętrznych iteracji zapisanych za pomocą Fluent API, to znaczy logika iteracji po elementach jest dla nasz ukryta a skupiamy się na ich przetwarzaniu.
List <String> namesNewJava = students.stream()
.map(student -> student.getName())
.filter (name-> name.startsWith("A"))
.collect (Collectors.toList());Operacje na strumieniach
Operacja na strumieniach dzielimy na pośrednie i końcowe (terminalne). Operacje pośrednie zwracają jako wynik działania strumień. W powyższym przykładzie takimi operacjami są map i filter. Operacje terminalne kończą przetwarzanie, zwykle agregują one wyniki, zliczają wartości, albo też nic nie wykonują (np. operacja foreach może być terminalna). Powyżej przykładem takiej operacji jest collect.
Dla operacji numerycznych stworzono specjalne strumienie IntStream, DoubleStream, and LongStream.
IntStream.rangeClosed(1, 10).forEach(num -> System.out.print(num));
// ->12345678910
IntStream.range(1, 10).forEach(num -> System.out.print(num));
// ->123456789Budowa strumieni
Stream stałych i elementów tablicy:
Stream.of("This", "is", "Java8", "Stream").forEach(System.out::println);
String[] stringArray = new String[]{"Streams", "can", "be", "created", "from", "arrays"};
Arrays.stream(stringArray).forEach(System.out::println);Elementy strumieni
Aby przetworzyć obiekt na strumień wykorzystujemy metode stream(). Następnie korzystamy z operacji by przetwarzać dane strumieniowe.
Task 6: Best friend
Zobacz jakiego typu jest poniższy obiekt:
whatIsIt = students.stream().filter(s -> s.getName().length() > 2);Filter
Wybiera elementy ze strumienia względem danego warunku
students.stream()
.filter(student -> student.getScore() >= 60)
.collect(Collectors.toList());Map
Zmienia przetwarzany element na coś innego, czyli pobiera element jednego typu i zwraca element innego typu. W praktyce najczęściej służy do wyciągnięcia jakiś atrybutów z obiektów.
students.stream()
.map(Student::getName)
.collect(Collectors.toList());The Student::getName jest tzw. method reference, skrótowym odwołaniem się do metody z klasy. Czyli na obiekcie typu Student, który przyjdzie ze streama wywołujemy metodę getName(), zadziała tylko z obiektem odpowiedniego typu.
Równoważnie możemy zapisać taki strumień jako:
students.stream()
.map(student -> student.getName())
.collect(Collectors.toList());Distinct
Usuwa powtórzenia
students.stream()
.map(Student::getName)
.distinct()
.collect(Collectors.toList());Limit
Ogranicza liczbę elementów w strumieniu do podanej liczby.
Sorted
Sortuje elementy w naturalnym dla nich porządku.
students.stream()
.map(Student::getName)
.sorted()
.collect(Collectors.toList());Z pomocą klasy Comparator możemy definiować sortowania różnego typu
//Sorting names if the Students in descending order
students.stream()
.map(Student::getName)
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
//Sorting students by First Name and Last Name both
students.stream()
.sorted(Comparator.comparing(Student::getFirstName).
thenComparing(Student::getLastName))
.map(Student::getName)
.collect(Collectors.toList());
//Sorting students by First Name Descending and Last Name Ascending
students.stream()
.sorted(Comparator.comparing(Student::getFirstName)
.reversed()
.thenComparing(Student::getLastName))
.map(Student::getName)
.collect(Collectors.toList());FlatMap
Działa podobnie jak mapa, tylko jako wynik zwraca strumień przetworzonych elementów.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
List<List<Integer>> mapped =
numbers.stream()
.map(number -> Arrays.asList(number -1, number, number +1))
.collect(Collectors.toList());
System.out.println(mapped); //:> [[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]]
List<Integer> flattened =
numbers.stream()
.flatMap(number -> Arrays.asList(number -1, number, number +1).stream())
.collect(Collectors.toList());
System.out.println(flattened); //:> [0, 1, 2, 1, 2, 3, 2, 3, 4, 3, 4, 5]Elementy Terminalne
Collect
Zbiera elementy strumienia w listę.
students.stream()
.filter(student -> student.getScore() >= 60)
.collect(Collectors.toList());Ważne: Collect zwraca nowy obiekt! Nową listę, mapę, zbiór etc. ale wartości są te same co w przetwarzanej kolekcji.
grupowanie i partycjonowanie
Map<Long, List<Student>> studentsByYear = students.stream()
.collect(groupingBy(Student::getYear));
Map<Boolean, List<Student>> groups =
students.stream().collect(Collectors.partitioningBy(s -> s.getName().startsWith("A")));Match
Match stosujemy gdy interesuje nas występowanie w strumieniu elementu o danych własnościach.
//Check if at least one student has got distinction
Boolean hasStudentWithDistinction = students.stream()
.anyMatch(student -> student.getScore() > 80);
//Check if All of the students have distinction
Boolean hasAllStudentsWithDistinction = students.stream()
.allMatch(student -> student.getScore() > 80);
//Return true if None of the students are over distinction
Boolean hasAllStudentsBelowDistinction = students.stream()
.noneMatch(student -> student.getScore() > 80);Find
Pozwala znajdować obiekt w strumieniu o danych włanościach, możemy wybrać dowolny dopasowany obiekt lub pierwszy dopasowany.
//Returns any student that matches to the given condition
students.stream().filter(student -> student.getAge() > 20)
.findAny();
//Returns first student that matches to the given condition
students.stream().filter(student -> student.getAge() > 20)
.findFirst();Reduce
Pozwala zredukować strumień danych do pojedynczej wartości.
//Summing without passing an identity
Optional<integer> sum = numbers.stream()
.reduce((x, y) -> x + y);
//Product without passing an identity
Optional<integer> product = numbers.stream()
.reduce((x, y) -> x * y);ForEach
Wykonanie operacji dla każdego elementu z listy.
students.stream()
.filter(student -> student.getScore() >= 60)
.foreach(student -> {
System.out.println("Brawo");
student.assignGradeInUsos(5);
});RemoveIf
Usuwanie (w miejscu!) elementów z kolekcji spełniających zadany warunek.
students.removeIf(student -> student.getScore() >= 60)Task 7: Streams
Zaimplementuj korzystając ze strumieni brakujące metody w klasie Tasks. Spradź uruchamiając TasksTest czy dobrze wykonałeś zadanie.
Zmienne lokalne w strumieniach
Poniższy kod się nie skompiluje:
int i = 0;
IntStream.range(1, 10).forEach(number -> {
if (number < i) {
System.out.println("Smaller");
i++;
}
});Podstawowym powodem, dla którego kompilacja się nie powiedzie, jest przechwycenie przez lambda wyrażenie wartości i, co oznacza wykonanie jej kopii w momencie inicjalizacji. Wymuszenie, by zmienna była ostateczna, pozwala uniknąć wrażenia, że zwiększenie i wewnątrz lambda mogłoby faktycznie zmodyfikować parametr metody i.
Podczas gdy to się skompiluje:
private int i =0;
public void method() {
IntStream.range(1, 10).forEach(number -> {
if (number < i) {
System.out.println("Smaller");
i++;
}
});
}Mówiąc najprościej, chodzi o to, gdzie przechowywane są zmienne składowe. Zmienne lokalne znajdują się na stosie, ale zmienne globalne składowe są na stercie. Ponieważ mamy do czynienia z pamięcią sterty, kompilator może zagwarantować, że lambda będzie miała dostęp do najnowszej wartości zmiennej.
Z drugiej strony zmiana wartości zmiennych w strumieniu może powodować problemy podczas ich równoległego wykonywania, dlatego jest uznawana za złą praktykę. Strumienie powinny być bezstanowe i jako takie nie wymieniać między sobą informacji (zmiennych, parametrów itp).
IntStream stream = IntStream.range(1, 100);
stream.parallel().forEach(number -> {
if (number > i) {
System.out.println(i + " smaller than + number);
i+=2;
}
});Laziness
W teorii języka programowania leniwa ewaluacja (lazy evaluation) lub call-by-need jest strategią ewaluacji, która opóźnia ocenę wyrażenia, dopóki nie będzie potrzebna jego wartość. W Java 8 Streams API potoki są konstruowany leniwie i przechowywane jako zestaw instrukcji. Dopiero gdy wywołamy operację terminalną, potok zostaje uruchomiony.
Innymi słowy, strumienie są leniwe, ponieważ operacje pośrednie nie są oceniane, dopóki nie zostanie wywołana operacja terminala (może nawet nigdy, jeśli strumienie nie zawierają terminala!). Dzięki temu strumienie mogą przetwarzać duże zbiory danych z wysoką wydajnością.
Gdy operacja terminala kończy się w czasie końcowym, nawet jeśli dane wejściowe ze strumienia są nieskończone, nazywa się to short-circuiting. Java 8 Streams API optymalizuje przetwarzanie strumienia za pomocą operacji short-circuiting. Metody Short Circuit kończą przetwarzanie strumienia, gdy tylko zostaną spełnione ich warunki.
// lazy evaluation - it does not matter where you put the limit
IntStream.range(1, 100)
.map(a -> {
if (a > 10) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return a;
}).limit(5)
.forEach(a -> System.out.println(a));Operacje pośrednie są podzielone na operacje bezstanowe i stanowe. Operacje bezstanowe, takie jak filtr i mapowanie, nie zachowują stanu z poprzednio widzianego elementu podczas przetwarzania nowego elementu — każdy element może być przetwarzany niezależnie od operacji na innych elementach. Operacje stanowe, takie jak distinct i sorting, mogą uwzględniać stan z poprzednio widzianych elementów podczas przetwarzania nowych elementów.
Operacje stanowe mogą wymagać przetworzenia wszystkich danych wejściowych przed wygenerowaniem wyniku.
Task 8: Sorting
Sprawdź efekt wywołania jeżeli posortujemy stream przed limit.
Stream.of("Sun", "Set", "Run", "Stream").filter(word -> {
System.out.println(word);
return word.startsWith("S");
}).limit(2).forEach(System.out::println);Czy wynik zmienia się wraz ze zmianą miejsca sorted() ? Teraz miejsce limit jest istotne! Czy kolejność operacji jest taka sama przy sortowaniu lub bez niego.
Eclipse collections
Kolekcje służą do przechowywania elementów w określonej kolejności, która pozwala na sprawne znalezienie elementów, wydajne wykorzystanie pamięci lub zapisywania elementów w określonej kolejności. Przykładami są Zbiory (Set), mapy (Map), kolejki (Queue) itp.
Implementacje kolekcji z biblioteki Eclipse Collections zapewniają efektywną pamięciowo implementację zbiorów i map, a także kolekcji podstawowych kolekcje.
Eclipse Collections powstało jako struktura kolekcji o nazwie Caramel wykorzystywana wewnętrznie przez bank Goldman Sachs w 2004 roku. po paru latach projekt został przeniesiony do open source pod nazwą GS Collections, a następnie do Eclipse Foundation, pod ostateczną nazwą Eclipse Collections w 2015 roku. Projekt jest w pełni otwarty i darmowy.
Zależność Mavena:
<dependency>
<groupId>org.eclipse.collections</groupId>
<artifactId>eclipse-collections-api</artifactId>
<version>9.2.0</version>
</dependency>
<dependency>
<groupId>org.eclipse.collections</groupId>
<artifactId>eclipse-collections</artifactId>
<version>9.2.0</version>
</dependency>Struktury zaimplementowane w kolekcjach Eclipse są zwykle szybsze i zajmują mniej pamięci niż te z java.util. W kolekcjach Eclipse można ponadto znaleźć dodatkowe struktury, których nie można znaleźć w java.util. Jednym z nich jest MultiMapa.
MultiMapa to mapa, do której każdemu kluczowi można przypisać więcej niż jedną wartość. Wartości na mapie są następnie zapisywane jako lista wartości połączona z kluczem.
Przykład:
FastListMultimap<String, String> citiesToPeople = FastListMultimap.newMultimap();
citiesToPeople.put("Poznan", "Nowak");
citiesToPeople.put("Poznan", "Kowalski");
citiesToPeople.get("Poznan")
.forEach(name -> System.out.println(name));Więcej przykładów:
i o tym jak należy wykonać collect by otrzymać element z biblioteki EclipseCollection.
- *
Used materials from: