Pracownia Programowania
Spring Boot
Uwaga! cały kod znajduje się na gałęzi SpringBootStart w repozytorium https://github.com/WitMar/PRA2024 . Kod końcowy w gałęzi SpringBootEnd.
Jeżeli nie widzisz odpowiednich gałęzi na GitHubie wykonaj Ctr+T, a jak to nie pomoże to wybierz z menu VCS->Git->Fetch.
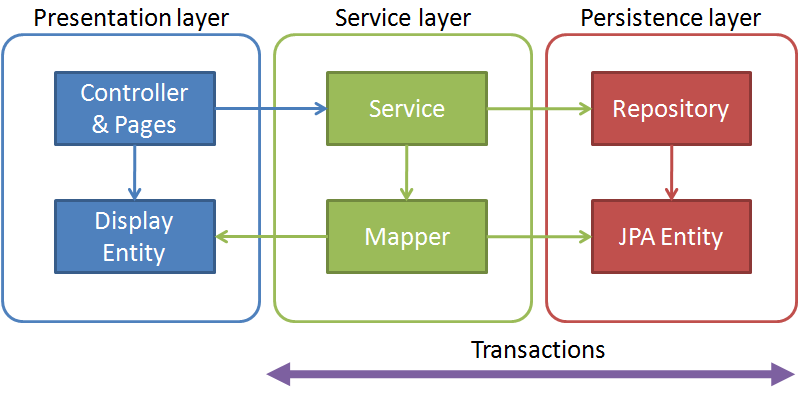
Trójwarstwowy model aplikacji
Aplikacje tworzone w SpringBoot w większości oparte są o model architektury trójwartswowej:
warstwa prezentacji : Controller, Pages, Display beanswarstwa serwisów : Services, Mapper between JPA entities and display beanswarstwa persystencji : JPA DAOs Repositories, JPA entities
Spring Boot
Spring Boot to lekki framework pozwalający na proste tworzenie aplikacji w oparciu o framework Spring. Spring Framework jest to platforma, której głównym celem jest uproszczenie procesu tworzenia oprogramowania w technologii Java/J2EE. Rdzeniem Springa jest kontener wstrzykiwania zależności, który zarządza komponentami i ich zależnościami. Obiekty zarządzane przez Springa nazywane są beanami.
O samym springu mówiliśmy na poprzednich zajęciach.
Startery (zależności definiowane w pliku pom.xml) są grupami zależności, które pozwalają na uruchamianie projektów Springowych minimalizując wysiłek ich konfiguracji.
W naszym przypadku głównym starterem będzie:
spring-boot-starter-web służy do budowania aplikacji opartych na REST API z wykorzystaniem Spring MVC oraz serwera aplikacji Tomcat.
Podany wyżej starter sprawia, że projekt jest konfigurowany do tego by korzystać z :
Wbudowanego Serwera TomcatHibernate for Object-Relational Mapping (ORM)Apache Jackson for JSON bindingSpring MVC for the REST framework
Pełną listę starterów można znaleźć tutaj:
Aplikacje przy użyciu Springa, buduje się modułowo. Idealnie wpasowuje się to w model MVC i pozwala na iteracyjny rozrost naszej aplikacji o kolejne moduły.
Jeżeli pozwolisz (przy użyciu adnotacji @EnableAutoConfiguration) Spring Boot dokona w jak najszerszym sensie automatycznej konfiguracji projektu - wyszuka odpowiednie adnotacje i powoła obiekty do życia.
Do generowania szkieletu aplikacji springowej możemy także posłużyć się stroną:
Który wyprodukuje szkielet aplikacji mavenowej wraz z zależnościami.
Konfiguracja ustawień
Konfiguracja znajduje się w pliku application.yml
Wykorzystanie bazy in-memory HSQL
## Spring DATASOURCE (DataSourceAutoConfiguration & DataSourceProperties)
spring:
jpa:
properties:
hibernate:
dialect: org.hibernate.dialect.HSQLDialect
ddl-auto: create
show-sql: true
database:
driverClassName: org.hsqldb.jdbcDriver
datasource:
url: jdbc:hsqldb:mem:spring
username: sa
password:Analogiczne ustawienia dla standardowej instalacji lokalnej bazy PostgeSQL wyglądałyby następująco:
## Spring DATASOURCE (DataSourceAutoConfiguration & DataSourceProperties)
spring:
jpa:
database: POSTGRESQL
properties:
hibernate:
dialect: org.hibernate.dialect.PostgreSQL94Dialect
ddl-auto: create
show-sql: true
database:
driverClassName: org.postgresql.Driver
datasource:
platrform: postgres
url: jdbc:postgresql://localhost:5432/postgres
username: postgres
password: postgresUstawienia dotyczą głównie dostępu do bazy danych i są takie same jak dla Hibernate.
Uwaga! dla spring.jpa.hibernate.ddl-auto znów najlepszą opcją byłoby update. Jeżeli jednak mamy problemy z uruchomieniem warto korzystać z create i validate.
Ważne jest także to, że wiele elementów ustawień jest zależnych od silnika bazy danych, z którego korzystamy.
Konfiguracja zależności
W pliku POM definiujemy:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
</parent>Jest to definicja wersji Spring Boota z jakiej korzystamy (2.7.3) ale także tzw. parent POM, dzięki czemu w naszym pliku POM możemy dziedziczyć wersje bibliotek z rodzica POM, tak by była między nimi pełna kompatybilność.
Możemy więc w pliku POM zdefiniować:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>Bez określania wersji i parametr ten zostanie wydziedziczony z parent POM (o ile są tam zdefiniowane). Zobacz pakiety i ich wersje na stronie :
Sterownik połączenia z bazą danych:
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>Uwaga! Jeżeli chcemy korzystać z innej bazy danych niż PostgreSql to musimy w pliku POM zdefiniować zależnośc względem sterownika tejże bazy.
Do budowania aplikacji używamy następujących wtyczek, które budują JAR (a następnie z niego) plik WAR. Ta wersja powinna budowania powinna być kompatybilna ze wszystkimi wersjami Javy.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<dependencies>
<dependency>
<groupId>org.codehaus.plexus</groupId>
<artifactId>plexus-archiver</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.0</version>
<dependencies>
<dependency>
<groupId>org.codehaus.plexus</groupId>
<artifactId>plexus-archiver</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<dependencies>
<dependency>
<groupId>org.codehaus.plexus</groupId>
<artifactId>plexus-archiver</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
</configuration>
</plugin>
</plugins>
</build>Uruchomienie
Główną klasą projektu jest klasa SpringApp. Znajduje się w niej funkcja main, inaczej mówiąc będzie to klasa, którą chcemy uruchamiać.
Aby uruchomić aplikację Springową potrzebujemy klasę wejściową opatrzoną adnotacją @SpringBootApplication, oraz wywołanie metody statycznej run() na klasie SpringApplication.
Przed klasą znajdują się adnotacje
@SpringBootApplication
@EnableJpaRepositories("com.pracownia.spring.repositories")Pierwsza jest tak naprawdę jest zbiorem kilku innych adnotacji (@Configuration (informacja, że obsługujemy żądania HTTP), @EnableAutoConfiguration (dzięki niej, aplikacja dokona samokonfiguracji według domyślnych wartości, załaduje potrzebne moduły itp.) oraz @ComponentScan (informacja, że ma przeskanować projekt w poszukiwaniu adnotacji odnośnie entity, repository, service i controller i je załadować)), informujemy tym samym, że dana klasa może być klasą rozruchową dla Springa, i zawiera w sobie podstawową konfigurację.
Ta sama klasa zwierać będzie ustawienia Springa (analogicznie do poprzednich zajęć była to klasa w której definiowaliśmy samodzielnie beany).
Aby uruchomić serwis wystarczy kliknąć prawym klawiszem na klasie SpringApp.java i wybrać Run. Spring Boot uruchamia wbudowany serwis aplikacji i nazwie Tomcata za nas i wgrywa tam aplikację, abyśmy sami mogli się skupić na tworzeniu kodu zamiast przejmowania się szczegółami technicznymi.
Tomcata uruchamia się domyślnie na porcie 8080, jeżeli ten port jest zajęty na Twoim komputerze aplikacja się nie uruchomi. Korzystając z konfiguracji ustawień możesz zmienić port na inny.
Klasa SpringApp rozszerza SpringBootServletInitializer, nie jest to wymagane, ale w przypadku gdy chcemy zbudować plik WAR i uruchomić go na serwerze Tomcat to musimy dodać ten element, przyda się on nam na kolejnych zajęciach.
Test
W projekcie zdefiniowany jest pusty test z adnotacjami.
@RunWith(SpringRunner.class)
@SpringBootTestPowoduje on uruchomienie środowiska springowego (bez połączenia z bazą danych). Dzięki czemu możemy łatwo sprawdzić w momencie budowania, czy nie występują błedy w definicji ustawień i środowiska Springowego.
Swagger
Uwaga! jeżeli uruchamiamy Springa poprzez główną klasę z Intellij nasz serwis będzie dostępny pod adresem http://localhost:8080/. Stąd jeżeli chciałbyś użyć postmana do komunikacji z serwisem korzystaj z tego adresu + ścieżki w ramach aplikacji.
Zadanie
Na poprzednich zajęciach widziałeś dokumentację API wygenerowaną przez bibliotekę Swagger. Nie jest ona standardowym elementem Spring Boota, aby dodać swaggera do projektu musisz wykonać następujące kroki. Dodaj do pom.xml (ten jeden krok jest już wykonany za Ciebie):
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.6.1</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.6.1</version>
<scope>compile</scope>
</dependency>Dodaj do application.yml
spring:
mvc:
pathmatch:
matching-strategy: ant_path_matcherOraz do klasy SpringApp
@Bean
public Docket productApi() {
return new Docket(DocumentationType.SWAGGER_2)
.select().apis(RequestHandlerSelectors.basePackage("com.pracownia.spring.controllers"))
.build();
}oraz adnotację @EnableSwagger2 przed nazwą klasy.
Uruchom klasę SpringApp sprawdź w przeglądarce na http://localhost:8080/swagger-ui.html# czy swagger działa.
Zadanie
Uruchom aplikację. Następnie wygeneruj obiekty metodą generateModel w indexController.
Zobacz jak w obu przypadkach serializują się obiekty wywołując metody get na api/products oraz api/sellers.
Serializer
Zadanie
Zobacz, jak obiekt daty jest serializowany (wywołaj GET dla dowolnego obiektu).
Podobnie jak na zajęciach z Jacksona, jeżeli chcielibyśmy zmienić format serializacji daty możemy tego dokonać ustawieniami na mapperze. Skąd jednak pobrać mapper używany przez Springa ? Najłatwiej jest zdefiniować własny mapper i przekazać go w konfiguracji Springa.
dodaj do POM:
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-joda</artifactId>
<version>2.0.4</version>
</dependency>Zobacz czy serializacja sie zmieniła.
Następnie dodaj do klasy SpringApp wsktrzykniecie własnego Mappera z własnymi ustawieniami:
@Bean
public MappingJackson2HttpMessageConverter mappingJackson2HttpMessageConverter() {
MappingJackson2HttpMessageConverter jsonConverter = new MappingJackson2HttpMessageConverter();
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(new JodaModule());
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
jsonConverter.setObjectMapper(objectMapper);
return jsonConverter;
}zobacz, jak data jest teraz serializowana (zrestartuj aplikację i wywołaj GET na obiekcie). Co stanie się jak zmienię SerializationFeature.WRITE_DATES_AS_TIMESTAMPS z disable na enable?
Controller
Kontroler to klasa odpowiedzialna za komunikację ze światem zewnętrznym (odpowiedź na zapytania z zewnątrz). W tym miejscu definiować będziemy endpointy REST API, czyli odpowiednie zachowania na zapytania HTTP.
Przed nazwą klasy kontrolera umieszczamy adnotację @RestController, by dać znać Springowi, że dana klasa jest kontrolerem.
Dodatkowo możemy zdefiniować na klasie adnotację
@RequestMapping("/api")Która spowoduje, że do wszystkich ścieżek zdefiniowanych w klasie dodany zostanie przedrostek "/api".
Konkretne metody API definiujemy za pomocą adnotacji. Nazwa adnotacji wskazują na metodę HTTP.
@GetMapping(value = "/products", produces = MediaType.APPLICATION_JSON_VALUE)oznacza zestaw mapowania funkcji metody GET. tj. jeśli adres główny naszej aplikacji to http://localhost:8080/myApp, to w celu pobrania naszych danych będziemy musieli podać adres: http://localhost:8080/myApp/api/products. Drugi parametr mówi o tym, że zwracane dane mają być serializowane do postaci JSON.
Spring używa Jacksona do serializacji i deserializacji danych.
Parametrami metody są parametry z nagłówka i ciało zapytania HTTP jak i ścieżka zapytania. Jeżeli chcemy odczytać dane ze ścieżki skorzystamy w definicji parametru z adnotacji @PathVariable i nazwy którą kojarzymy z nazwą z parametry value umieszczoną w klamrach.
@GetMapping(value = "/product/{id}", produces = MediaType.APPLICATION_JSON_VALUE)
public Product getByPublicId(@PathVariable("id") Integer publicId)W przypadku, gdy przekazujemy dane poprzez parametr zapytania HTTP (czyli ?param=value) stosujemy adnotację @RequestParam i nazwę paramteru taką jaka będzie w komunikacie HTTP.
@GetMapping(value = "/product", produces = MediaType.APPLICATION_JSON_VALUE)
public Product getByParamPublicId(@RequestParam("id") Integer publicId)W przypadku, gdy chcemy odczytać ciało zapytania HTTP stosujemy adnotację @RequestBody.
@PostMapping(value = "/product")
public ResponseEntity<Product> create(@RequestBody Product product)W przypadku zwracanych parametrów możemy także zwracać obiekty klas i przez parametr produces określać sposób ich deserializacji lub dodać adnotację @ResponseBody (mówi, że zwracany obiekt to JSON i zapisuje go do body komunikatu HTTP). Możemy także definiować standardowe komunikaty HTTP używając klasy ResponseEntity<>(HttpStatus.XXX); lub też w odpowiedzi przekierować zapytanie do innego endpointa poprzez zastosowanie new RedirectView("/api/products", true);. Bądź ostrożny, ponieważ RedirectView nie zmienia metody HTTP, tzn. przekierowanie z metody DELETE wysyła żądanie DELETE do przekierowanego adresu URL.
@DeleteMapping(value = "/product/{id}")
public RedirectView delete(@PathVariable Integer id) {
productService.deleteProduct(id);
return new RedirectView("/api/productsList", true);
}Zadanie
Zobacz jak zachowuje się endpoint delete.
Zadanie
Dobrą praktyką w przypadku tworzenia obiektów w REST API jest zwracać ścieżkę do obiektu, lub cały obiekt w odpowiedzi (jako potwierdzenie / podanie użytkownikowi id stworzonego obiektu). Zamień sposób odpowiedzi na zapytanie POST na poniższą linijkę:
ResponseEntity.ok().body(product);Wywołaj POST dla obiektu
{
"bestBeforeDate": "2022-12-11T19:21:25.099Z",
"name": "kartofel",
"price": 10
}Zobacz różnice w odpowiedzi pomiędzy POST a PUT.
Entity
Model danych jest klasą zawierającą klasy i pola takie jak w przypadku projektu Hibernatowego i oznaczane są adnotacją @Entity przed nazwą klasy.
Możemy w nich korzystać z klasycznych adnotacji Hibernatowych (jak i np Jacksonowych).
Przypomnienie: Hibernate potrzebuje żeby w klasie był bezargumentowy konstruktor!
Podejrzyj klasy Product i Seller żeby zobaczyć jak wyglądają modele w naszej aplikacji.
Repository
Do zarządzania danymi (wykonywaniem zapytań na bazie danych) w projekcie springowym służą repozytoria. Repozytoria będą definiować jakie operacje możemy wykonać na naszych danych. Podstawowe operacje CRUD (Create, Read, Update, Delete) dostajemy od Springa, inne operacje jak wyszukiwanie po polach musimy dodać sami.
Żeby używać repozytoriów musimy do klasy Main musimy dodać adnotację @EnableJpaRepositories i (opcjonalnie) określić ścieżkę, w której się znajdują.
Najprostsze repozytoria tworzone są jako interfejsy. Repozytorium definiujemy osobno dla każdej encji - czyli dla każdej tabeli w bazie. Poprawna implementacja interfejsu, która jest potrzebna do wykonania metod jest generowana przez Springa.
public interface ProductRepository extends CrudRepository<Product, Integer>Definiuje najprostsze repozytorium, które dziedziczy najprostsze operacje CRUD ze springowego repozytorium Crud (nie musimy sami już pisać tych zapytań).
Product to klasa (obiekt) jaki chcemy przechowywać - w bazie danych będzie to tabela, u nas w projekcie jest to klasa modelu.Integer to typ klucza dla tabeli productów.
- Lista operacji z interfejsu CRUD:
- Product save(Product t) – zapisz produkt do bazy danychIterable save(Iterable t) – zapisanie kolekcji obiektówProduct findOne(Integer id) – znajduje wpis z kluczem podanym jako parametrboolean exists(Integer id) – sprawdź czy wpis z kluczem istniejeIterable findAll() – pobierz wszystkie wpisy z tabliIterable findAll(Iterable IDs) – znajdź wszystkie elementy z kluczami na liście IDslong count() – policz elementy w tabelivoid delete(Integer id) – usuń element z kluczem idvoid delete(Product r) – usuń obiekt z tabelkivoid delete(Iterable IDs) – usuń wszystkie obiekty których klucze znajdują się na liście IDsdeleteAll() – wyczyść tabelę
Oczywiście możemy dziedziczyć po więcej niż jednym interfejsie. Zwracamy uwagę na PagingAndSortingRepository ułatwiające stronnicowanie przy pobieraniu obiektów z bazy.
Zapytania SQL możemy w Springu tworzyć na 4 sposoby:
* Zapytania "nazwane"* Query DSL* Z nazw metod* @Query Annotation
DSL to zapytania tworzone w kodzie:
queryFactory.selectFrom(person)
.where(
person.firstName.eq("John"),
person.lastName.eq("Doe"))
.fetch();Więcej przykładów na https://www.baeldung.com/querydsl-with-jpa-tutorial .
Poniżej przedstawimy dwa ostatnie sposoby:
Definiowanie własnych zapytań odbywa się poprzez:
Zdefiniowanie metody w interfejsie
List<Product> findByName(String name);Spring automatycznie zmienia metodę na zapytanie SQL (za nas) jeżeli stosujemy się do odpowiedniej konwencji nazewniczej.
Kluczowe frazy to find…By, read…By, and get…By możemy do tego używać nazw pól oraz logicznych spójników And i Or.
Tutaj Spring domyśla się co ma zrobić po nazwie metody. Można by w podobny sposób zapisać findByName(String name). Możemy również łączyć warunki i tworzyć nazwy takie jak findByDoneAndName(Boolean done, String name). Przykład:
public interface PersonRepository extends Repository<User, Long> {
List<Person> findByEmailAddressAndLastname(EmailAddress emailAddress, String lastname);
// Enables the distinct flag for the query
List<Person> findDistinctPeopleByLastnameOrFirstname(String lastname, String firstname);
List<Person> findPeopleDistinctByLastnameOrFirstname(String lastname, String firstname);
// Enabling ignoring case for an individual property
List<Person> findByLastnameIgnoreCase(String lastname);
// Enabling ignoring case for all suitable properties
List<Person> findByLastnameAndFirstnameAllIgnoreCase(String lastname, String firstname);
// Enabling static ORDER BY for a query
List<Person> findByLastnameOrderByFirstnameAsc(String lastname);
List<Person> findByLastnameOrderByFirstnameDesc(String lastname);
}Więcej przykładowych słów kluczowych w użyciu:
Drugi sposób to zdefiniowanie zapytania samemu korzystając z adnotacji @Query przed nazwą metody w interfejsie. Zapytania definiujemy w znanym z Hibernate standardzie JPQL, który jest wzorowany na HQL i w większości jest jego podzbiorem.
@Query("select u from User u where u.age = ?1")
List<User> findUsersByAge(int age);
@Query("select u from User u where u.firstname = :#{#customer.firstname}")
List<User> findUsersByCustomersFirstname(@Param("customer") Customer customer);Parametry zapytań są definiowane poprzez adnotacje @Param lub poprzez numer parametru w definicji ?1.
Zadanie
> Zobacz w repository Seller zapytanie wyszukujące sprzedawcę po nazwie.
> Dodaj do repository Seller zapytanie wyszukujące produkty które sprzedaje sprzedawca.
@Query("select p from Seller s join s.productsOb p where s.id = ?1")
List<Product> getProductsById(Integer id);> Druga wersja tego zapytania (przy wykorzystaniu tablicy productId):
@Query("select p from Seller s join s.products ps, Product p where p.productId = ps.id and s.id = ?1")
List<Product> getProductsById(Integer id);> Dodaj do repository Seller zapytanie podające sumę cen produktów danego sprzedawcy
@Query("select sum(p.price) from Seller s join s.productsOb p where s.id = ?1")
Long countSumOfProductCosts(Integer id);Service
Jak zauważyliśmy powyżej repository definiuje bezpośredni dostęp do danych poprzez zapytania bazy danych. Z punktu widzenia inżyinerii repository nie zawiera więc żadnej logiki, tylko proste zapytania bazodanowe. Jeżeli potrzebujemy opakować naszą interakcję z bazą danych przez logikę biznesową zastosujemy tzw. service - czyli warstwę pośrednią między danymi a widokiem.
W celu zdefiniowania serwisu przed nazwą klasy serwisu umieszczamy adnotację @Service.
Spring wykorzystuje tzw. mechanizm wstrzykiwania zależności. To znaczy, że silnik springa jest odpowiedzialny za zarządzanie komponentami i przekazywanie ich do innych komponentów, tak by mogły być wykorzystywane razem. Kluczowa jest tu adnotacja
@AutowiredMówi ona springowi, że chcemy w tym miejscy pobrać obiekt komponentu zdefiniowany w systemie.
Np. w przypadku serwisu będzie nam potrzebny komponent Repository, na którym chcemy wykonywać zapytania.
@Autowired
private ProductRepository productRepository;Adnotacja taka spowoduje, że w obiekcie serwisu Spring zainicjalizuje zmienną productRepository niejako "za nas" a my będziemy mogli z niej dalej korzystać.
Dokładniej to co definiujemy to interfejs, którym możemy posługiwać się w naszej klasie a Spring wstrzykuje do niego implementację tego interfejsu. Stąd, aby utworzyć serwis definiujemy interfejs:
public interface ProductServicez nagłówkami metod. Jeżeli będziemy chcieli skorzystać w innej klasie z tego interfejsu zdefiniujemy go jako
@Autowired
private ProductService productService;Natomiast implementację metod zawrzemy w klasie ProductServiceImpl.
@Service
public class ProductServiceImpl implements ProductServiceDodamy teraz stronnicowanie do wyników zapytań o produkty.
Zadanie
Dodaj do Product repository : PagingAndSortingRepository.
public interface ProductRepository extends CrudRepository<Product, Integer>, PagingAndSortingRepository<Product, Integer> {Dodaj do serwisu zapytanie stronnicowane o produkty (zwróć uwagę, że teraz findAll może przyjmować parametr PageRequest - nr strony, wielkość strony). Uwaga strony są numerowane od zera!
@Override
public Iterable<Product> listAllProductsPaging(Integer pageNr, Integer howManyOnPage) {
return productRepository.findAll(PageRequest.of(pageNr,howManyOnPage));
}Dodaj kontroler:
@GetMapping(value = "/products/{page}", produces = MediaType.APPLICATION_JSON_VALUE)
public Iterable<Product> list(@PathVariable("page") Integer pageNr,@RequestParam(value = "size",required = false) Optional<Integer> howManyOnPage) {
return productService.listAllProductsPaging(pageNr, howManyOnPage.orElse(2));
}Zwróć uwagę na parametr size, który jest opcjonalny (i przy nie podaniu żadnej wartości ustawiamy go jako 2).
Zadanie
Zmień zapytanie seller/{id} tak by zwracało XML-a, a nie JSON-a. By to zrobić ustaw Media Type:
@GetMapping(value = "/seller/{id}", produces = MediaType.APPLICATION_XML_VALUE)
@ResponseBody
public ResponseEntity<Seller> getSellerByPublicId(@PathVariable("id") Integer publicId) {
Optional<Seller> seller = sellerService.getSellerById(publicId);
if(seller.isPresent()) {
return ResponseEntity.ok(seller.get());
} else
return ResponseEntity.noContent().build();
}oraz dodaj zależność do POM-a (nie dodano jej!) i odśwież Mavena (obowiązkowo!!)
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
</dependency>Zadanie
Dodaj endpoint do pobierania sumy cen produktów danego sprzedawcy.
Walidacja
Teraz dodamy walidację do pola encji i kontrolera.
Dodaj do pliku pom.xml zależność:
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency>W encji Produktu dodaj walidacje, by cena nie mogła być większa niż 6
@Column
@Max(value = 100)
private BigDecimal price;W kontrolerze Produktu w metodzie create dodaj walidacje
@PostMapping(value = "/product")
public ResponseEntity<Product> create(@RequestBody @NonNull @Valid
Product product)Aby przekazać użytkownikowi błąd powinniśmy przechwycić wyjątek za pomocą exception handlera :
@ExceptionHandler
@ResponseStatus(value = HttpStatus.BAD_REQUEST)
public String handleException(MethodArgumentNotValidException exception) {
return exception.getMessage();
}Zadanie
Spróbuj dodać poprzez POST, JSON z obiektem, który nie jest poprawnym obiektem Product, porównaj wynik z odpowiedzią dla niewalidowanego endpointa PUT.
{
"id":1,
"productId": "68e886e4-4d17-4b95-8408-3718fcb9f34c",
"name": "Chleb",
"price": 310.5,
"bestBeforeDate": "2021-12-12T14:06:54.280Z"
}http://silversableprog.blogspot.com/2015/11/javaspring-boot-jak-rozpoczac-pisanie-w.html
http://blog.mloza.pl/spring-boot-szybkie-tworzenie-aplikacji-web-w-javie/
http://blog.mloza.pl/spring-boot-interakcja-z-baza-danych-czyli-spring-data-jpa/#more-70
https://www.callicoder.com/spring-boot-rest-api-tutorial-with-mysql-jpa-hibernate/
https://spring.io/guides/tutorials/bookmarks/
https://github.com/Zianwar/springboot-crud-demo
https://kobietydokodu.pl/09-spring-mvc/
https://www.ibm.com/developerworks/library/j-spring-boot-basics-perry/index.html
https://sites.google.com/site/telosystutorial/springmvc-jpa-springdatajpa/presentation/architecture