Przetwarzanie równoległe i strumieniowe
Uwaga! Kod z którego będziemy korzystać na zajęciach jest dostępny na branchu StreamClassesStart w repozytorium https://github.com/WitMar/PRS2020 . Kod końcowy można znaleźć na branchu StreamClassesEnd.
Jeżeli nie widzisz odpowiednich gałęzi na GitHubie wykonaj Ctr+T, a jak to nie pomoże to wybierz z menu Git->Fetch.
Podsumowanie zajęć I
Co wiemy po pierwszych zajęciach:
* Projekt podzielony jest na katalogi: źródłowy - src, zasobów - resources.* Korzystamy z systemu zarządzania zależnościami MAVEN i w katalogu projektu umieszczony jest plik pom.xml odpowiadający za ustawienia Mavena.* Do wypisywania na ekran korzystamy z loggera. Ustawienia loggera znajdziemy w pliku log4.properties w katalogu resources.* Pracujemy na GIT - nowa funkcjonalność (nowy temat zajęć) zakładana jest na nowej gałęzi (ang. branch).
Synchronizacja kodu Git z oryginalnym repo
Po pierwsztch zajęciach powinieneś do projektu mieć dodane własne repozytorium, po zmianie na repozytorium prowadzącego niestety fork z poporzednich zajęć nie powoduje, że oba repozytoria są synchronizowane ciągle w przyszłości. Rozwiązaniem tego problemu jest dodanie wielu repozytoriów w ramach jednego projektu.
Przejdź do Git -> Manage Remotes
Dodaj wpis o repozytorium prowadzącego
nazwij je najlepiej jako PrzedmiotoweRepo
Wybierz Ctrl + T, aby odświeżyć zależności.
Jeżeli Ctrl+T z jakiegoś powodu nie ściągnie oczekiwanych zmian, to żeby wymusić ściągnięcie zmian wybierz Git -> fetch.
Wtedy na liście branchy w prawym dolnym rogu ekranu powinieneś widzieć gałęzie z repozytorium przedmiotowego jak i ze swojego.
Czasem przejście na nowy branch powoduje, że musisz ponownie skonfigurować mavena. Sprawdź czy ikonki przy klasach są zielonymi kółkami, jeżeli nie, spróbuj odświeżyć Mavena (dwie strzałki w kółko). Jeśli to nie pomoże wybierz mały plus i wskaż plik pom.xml z dysku twardego. Następnie odśwież ponownie Mavena. To powinno pomóc - sprawdź, czy twoje pliki .java mają zielone kółko obok nich w zakładce Project.

Debugowanie
Poprzez wybór Run -> Debug lub wybierając na klasie prawym przyciskiem myszy Debug możemy debugować nasz kod, czyli uruchamiać w kontrolowany sposób, tak by móc zatrzymywać w dowolnym momencie wywołanie kodu.
Czym jest debugowanie?
W celu debugowania dodajemy w kodzie tzw breakpointy czyli miejsca, w których chcemy zatrzymać wywołanie programu tak, by móc wykonywać dodatkowe operacje lub podejrzeć wartości zmiennych. Aby uruchomić kod lub uruchomić debuggowanie możesz też kliknąć na zielonego robaczka obok nazwy klasy.
Wejdź do klasy Debug Example.
Zadanie 1
Uruchom klasę i zobacz jaki da wynik
Dodaj w linijce 14 breakpointa - klikając obok numeru linii tak by pojawiło się czerwone kółko.
Uruchom debugowanie poprzez wybranie "zielonego robaczka". Sprawdź jak zmienia się wartość zmiennej silnia w kolejnych uruchomieniach.

Użyj F8 (lub strzałka w dół na panelu debugingu) aby przejść w wywołaniu kodu linijka po linijce.
Użyj StepInto F7 (strzała w prawo-dół na panelu debugingu) aby wejść w wywołanie metody.
Przechodź F9 (zielony trójkąt na panelu debug) do kolejnych wystąpień breakpointa i podglądaj wartości zmiennych.
Kolekcje
Kolekcje to struktury służące do przechowywania danych. Standardowe kolekcje są zaimplementowane i przetestowane dla nas w standardzie języka programowania, tak że możemy z nich swobodnie korzystać i być pewnym, że działają poprawnie.
Kolekcje w Java:
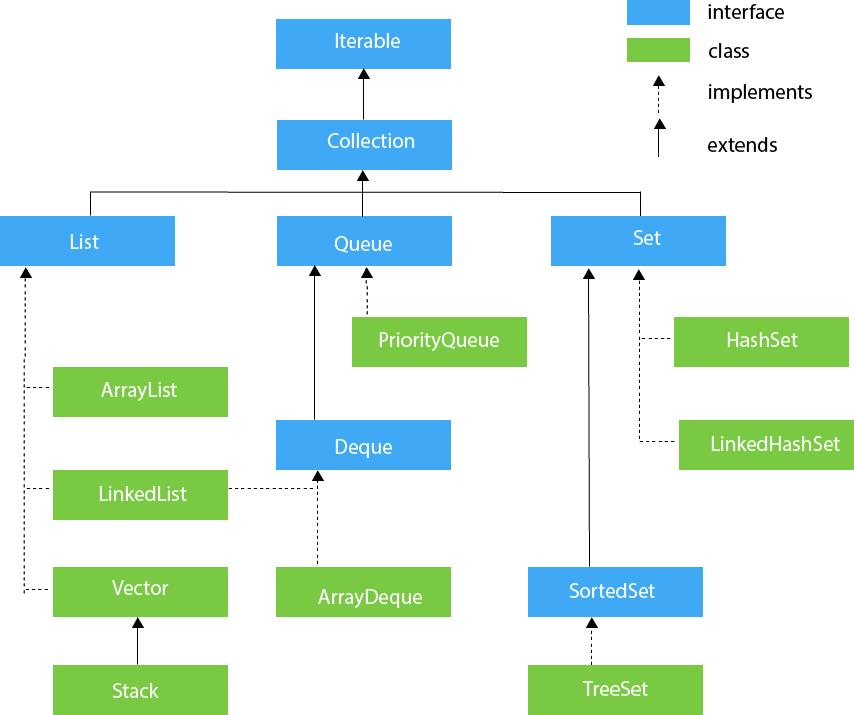

Przykłady:
List<Integer> list = new ArrayList<>();
Set<Integer> list = new HashSet<>();Zadanie 3
Otwórz klasy ListsExample i MapExample by zobaczyć więcej przykładów definiowania kolekcji w Javie. Wybierz nazwę zmiennej i dodaj kropkę by zobaczyć podpowiedzi na temat operacji możliwych do wykonania na danym obiekcie.
HashMap nie daje żadnej gwarancji wzlędem kolejności elementów na mapie.
Oznacza to, że nie możemy przyjąć żadnej kolejności podczas iteracji po kluczach czy wartościach hash mapy. Natomiast elementy w TreeMap są sortowane zgodnie z ich naturalną kolejnością :
Map<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "TreeMap");
hashMap.put(32, "vs");
hashMap.put(21, "HashMap");Większość kolekcji nie jest thread-safe, czyli w przypadku równoległego dostępu przez wiele wątków mogą zwracać niepoprawne rezultaty.
Zadanie 3
Otwórz klasę MultiThreadCollectionsExample i zobacz jakiego typu błąd możesz zaobserwować. Możesz ustawić punkt debuggowania by podejrzeć wartości na liście. Otwórz okno ewaluacji wyrażeń.

By podejrzeć listę np od końca, wpisz:
Collections.reverse(numbers);
numbersW kolejnych tyodniach poznamy kolekcje, które działają poprawnie w środowisku wielowątkowym.
Przetwarzanie strumieniowe
Przetwarzanie danych strumieniowych wiążę się także z pojęciem "programowanie funkcyjne", czyli przetwarzaniu za pomocą funkcji, które pozwalają nam przetwarzać dane w ciągu kolejno wykonywanych operacji. Jego najważniejsze własności to:
* Metody są łączone w łańcuchy wywołań tzn metoda1().metoda2().metoda3() itp, gdzie wynik działania poprzedniej metody jest parametrem wejściowym kolejnej.* Nazwa każdej metody powinna sugerować do czego służy.* Metody dzielimy na końcowe (terminalne) po których nie następują już kolejne kroki i pośrednie, które powinny mieć następnika. Każdy strumień przetwarzania powinien być zakończony metodą terminalną.
Do definiowania metod z interfejsów strumieniowych wykorzystujemy najczęściej funkcje anonimowe.
Funkcje anonimowe (lambdy)
Funkcją nazwiemy, podobnie jak w matematyce działanie, które dla zadanych argumentów zwraca wartość. Każda funkcja określona jest więc przez listę parametrów wejściowych, listę parametrów wyjściowych oraz ciało metody, czyli sposób transformacji danych wejściowych na wyjściowe.
Do definiowania funkcji stosujemy zazwyczaj tzw. wyrażenia Lamba o notacji a -> a + 10. Lewa strona strzałki oznacza argumenty (w tym przypadku pojedynczy argument), a prawa strona oznacza funkcję, która może skłądać się z jednej lub większej liczby instrukcji (w tym drugim przypadku należy użyć {}) : a -> { b = 10; return a+b; }.
Funkcje
Lambda wyrażenie możemy przypisać do zmiennej o typie function. Function to specjalny interfejs w javie do definiowania funkcji. Posiada on metody apply() służącą do uruchamiania.
Function<Integer, Double> divideByHalf = a -> a / 2.0;
// apply the function to get the result
double a = half.apply(10);Zadanie 2
Podejrzyj różne przykłady fukcji i lambda wyrażeń w klasie LambdaExample.
Strumienie
Tradycyjnie w Javie do przechodzenia po kolekcjach korzystaliśmy z jawnych iteratorów
List <String> names = new ArrayList <>();
for (Student student: students) {
if (student.getName ().startsWith("A")) {
names.add (student.getName ());
}
}Wykorzystując przetwarzanie strumieniowe korzystamy z tzw. wewnętrznych iteracji, to znaczy logika iteracji po elementach jest dla nasz ukryta a skupiamy się na ich przetwarzaniu.
List <String> namesNewJava = students.stream()
.map(student -> student.getName())
.filter (name-> name.startsWith("A"))
.collect (Collectors.toList());Budowa strumieni
Strumień to po prostu ciąg danych na których możemy wykonywać operacje. Charakteryzuje się on tym, że dane są niezależne od siebie (nie możemy zapytać o poprzedni lub następny element w strumieniu) oraz taki, że strumień danych może być "nieskonczony" - dane mogą przychodzić do strumienia na bieżąco i przed uruchomieniem nie znamy ich liczby.
Operacja na strumieniach dzielimy na pośrednie i końcowe (terminalne). Operacje pośrednie zwracają jako wynik działania strumień. W powyższym przykładzie takimi operacjami są map i filter. Operacje terminalne kończą przetwarzanie, zwykle agregują one wyniki, zliczają wartości, albo też nic nie wykonują (np. operacja foreach może być terminalna). Powyżej przykładem takiej operacji jest collect.
Dla operacji numerycznych stworzono specjalne strumienie IntStream, DoubleStream, and LongStream.
IntStream.rangeClosed(1, 10).forEach(num -> log.info(num));
// ->12345678910
IntStream.range(1, 10).forEach(num -> log.info(num));
// ->123456789Analogicznie dla kolekcji tworzymy strumień poprzez metodę stream(). Aby wyciągnąć dane z kolekcji do strumienia wykorzystujemy metode stream(). Następnie korzystamy z operacji by przetwarzać dane strumieniowe.
Zadanie 4
Zobacz jakiego typu jest poniższy obiekt:
whatIsIt = lista.stream();Skopiuj powyższy kod i wykonaj ALT+Enter by Intellij podpowiedział Ci jaki jest typ zmiennej.
Funkcje przetwarzania strumieni danych
Zadanie 5
Przechodząc przez kolejne funkcje wypełnij elementy oznaczone jako ToDo.
Filter
Wybiera elementy ze strumienia względem danego warunku
log.info("Students with name starting with A");
students.stream()
.filter(student -> student.getName().startsWith("A"))
.forEach(s -> log.info(s.getName()));Map
Zmienia przetwarzany element na coś innego, czyli pobiera element jednego typu i zwraca element innego typu. W praktyce najczęściej służy do wyciągnięcia jakiś atrybutów z obiektów.
log.info("Students with name starting with A");
students.stream()
.map(student -> student.getName())
.filter(student -> student.startsWith("A"))
.forEach(s -> log.info(s));
log.info("Students with name starting with A");
students.stream()
.map(Student::getName)
.filter(student -> student.startsWith("A"))
.forEach(s -> log.info(s));The Student::getName jest tzw. method reference, skrótowym odwołaniem się do metody z klasy. Czyli na obiekcie typu Student, który przyjdzie ze streama wywołujemy metodę getName(). Oba przykłady powyżej są równoważne.
Distinct
Usuwa powtórzenia
log.info("Students names");
students.stream()
.map(Student::getName)
.distinct()
.forEach(s -> log.info(s));Limit
Ogranicza liczbę elementów w strumieniu do podanej liczby.
log.info("Only 3 students names");
students.stream()
.map(Student::getName)
.distinct()
.limit(3)
.forEach(s -> log.info(s));Sorted
Sortuje elementy w naturalnym dla nich porządku. Dla zmiennych które Java zna jak long, int, string istnieją domyślne comparatory - czyli sposób ich porównywania. Jeżeli wykonamy metodę sorted() bez parametru zostanie użyty właśnie taki domyślny comparator.
log.info("Names list lexicographic");
students.stream()
.map(student -> student.getName())
.sorted()
.forEach(s -> log.info(s));Zauważmy, że dla klasy Student Java nie wie jak porównywać studentów między sobą. W związku z tym musimy zdefiniować w jaki sposób chcemy porównywać obiekty.
log.info("Best three results");
students.stream()
.sorted(Comparator.comparing(Student::getTestResults).reversed())
.map(student -> student.getName() + " " + student.getSurname() + " " + student.getTestResults())
.limit(3)
.forEach(s -> log.info(s));Z pomocą klasy Comparator możemy definiować sortowania złożone - po więcej niż jednym parametrze:
//Sorting students by First Name and Last Name both
students.stream()
.sorted(Comparator.comparing(Student::getName).
thenComparing(Student::getSurname))
.map(Student::getName)
.forEach(s -> log.info(s));
//Sorting students by First Name Descending and Last Name Ascending
students.stream()
.sorted(Comparator.comparing(Student::getName)
.reversed()
.thenComparing(Student::getSurname))
.map(Student::getName)
.collect(Collectors.toList());FlatMap
Działa podobnie jak mapa, tylko jako wynik zwraca strumień przetworzonych elementów, służy głownie do wypakowywania list elementów do pojedynczych obiektów (flat - spłaszczanie struktury danych).
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
List<List<Integer>> mapped =
numbers.stream()
.map(number -> Arrays.asList(number -1, number, number +1))
.collect(Collectors.toList());
System.out.println(mapped); //:> [[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]]
List<Integer> flattened =
numbers.stream()
.flatMap(number -> Arrays.asList(number -1, number, number +1).stream())
.collect(Collectors.toList());
System.out.println(flattened); //:> [0, 1, 2, 1, 2, 3, 2, 3, 4, 3, 4, 5]Elementy Terminalne
ForEach
Wykonanie operacji dla każdego elementu z listy.
log.info("Students with name starting with A");
students.stream()
.filter(student -> student.getName().startsWith("A"))
.forEach(s -> log.info(s.getName()));Match
Match stosujemy gdy interesuje nas sprawdzenie spełnienia jakiegoś warunku
//Check if at least one
Boolean hasStudentFailExam = students.stream()
.anyMatch(student -> student.getGrade() == 2);
//Check if All
Boolean hasAllStudentPassExam = students.stream()
.allMatch(student -> student.getGrade() > 2);
//Check if none
Boolean hasAllStudentPassExam = students.stream()
.noneMatch(student -> student.getGrade() == 2);Find
Pozwala znajdować obiekt w strumieniu o danych włanościach. Inaczej mówiąc sprawdza czy w strumieniu mamy jakieś dane. Możemy wybrać dowolny dopasowany obiekt lub pierwszy dopasowany.
Optional<Student> prymus = students.stream()
.filter(student -> student.getGrade() == 3)
.findAny();
Optional<Student> prymus = students.stream()
.filter(student -> student.getGrade() == 3)
.findFirst();Reduce
Pozwala zredukować strumień danych do pojedynczej wartości.
//Summing without passing an identity
Optional<integer> sum = numbers.stream()
.reduce((x, y) -> x + y);
//Product without passing an identity
Optional<integer> product = numbers.stream()
.reduce((x, y) -> x * y);RemoveIf
Usuwanie (w miejscu!) elementów z kolekcji spełniających zadany warunek.
//Remove students who fail exam
students.removeIf(student -> student.getGrade() == 2)Collect
Zbiera elementy strumienia w kolekcję.
log.info("Students with name starting with A");
List<Student> studentsWithAname = students.stream()
.filter(student -> student.getName().startsWith("A"))
.collect(Collectors.toList());Ważne: Collect zwraca nowy obiekt! Nową listę, mapę, zbiór etc. ale wartości są te same co w przetwarzanej kolekcji.
Grupowanie i partycjonowanie przez collect:
Map<Long, List<Student>> studentsByYear = students.stream()
.collect(groupingBy(Student::getYear));
Map<Boolean, List<Student>> groups =
students.stream().collect(Collectors.partitioningBy(s -> s.getName().startsWith("A")));Zmienne lokalne w strumieniach
Poniższy kod się nie skompiluje:
int i = 0;
IntStream.range(1, 10).forEach(number -> {
if (number < i) {
System.out.println("Smaller");
i++;
}
});W założeniu lambda jest bezstanowa i różne wywołania nie powinny w związku z tym współdzielić żadnych danych. Wynika to też z możliwości wywołania przetwarzania strumieniowego równolegle i problemów w przypadku współdzielenia zasobów. Ograniczenie to można obejśc stosując zmienną globalną, jednak zmiana wartości zmiennych w strumieniu może powodować problemy podczas ich równoległego wykonywania, dlatego jest uznawana za złą praktykę.
IntStream stream = IntStream.range(1, 100);
stream.parallel().forEach(number -> {
if (number > i) {
System.out.println(i + " smaller than " + number);
i+=2;
}
});Parallel stream
Domyślnie każda operacja strumieniowa w Javie jest przetwarzana sekwencyjnie, chyba że zostanie wyraźnie określona jako równoległa. Każdy strumień w Javie można łatwo przekształcić z sekwencyjnego na równoległy. Możemy to osiągnąć, dodając metodę parallel() do strumienia sekwencyjnego. Strumienie równoległe umożliwiają nam wykonywanie kodu równolegle na osobnych rdzeniach. Ostateczny wynik jest kombinacją każdego indywidualnego wyniku.
Jednak kolejność wykonania operacji jest w tym wypadku poza naszą kontrolą i może się ona zmieniać przy każdym uruchomieniu programu:
Zadanie 6
Uruchom przykład z Find zamieniając stream() na parallelStream() by zobaczyć jaki wpływ ma na wynik.
Przetwarzanie równoległe może być korzystne dla pełnego wykorzystania rdzeni procesora. Ale musimy również brać pod uwagę obciążenie związane z zarządzaniem wieloma wątkami, lokalizacją pamięci, dzieleniem źródła i łączeniem wyników. Np. prosta redukcja
IntStream.rangeClosed(1, 100).reduce(0, Integer::sum);
IntStream.rangeClosed(1, 100).parallel().reduce(0, Integer::sum);działa szybciej sekwencyjnie niż równolegle.
- *
Wykorzystano materiały z: