Stream
Strumień (stream) odnosi się do nieprzerwanego ciągu danych, który nie ma punktu początkowego ani końcowego.

Strumień (stream) odnosi się do nieprzerwanego ciągu danych, który nie ma punktu początkowego ani końcowego.
Dane strumieniowe to dane, które są generowane w sposób ciągły, zwykle w dużych ilościach i z dużą prędkością.
Strumieniowe źródło danych zazwyczaj składa się z ciągłych dzienników ze znacznikami czasu, które rejestrują zdarzenia na bieżąco — takie jak kliknięcie przez użytkownika łącza na stronie internetowej lub czujnik informujący o aktualnej temperaturze.
Przetwarzanie wsadowe (batch processing) - dane są gromadzone w partiach, po czym są przetwarzane, przechowywane lub analizowane w zależności od potrzeb.
Przetwarzanie strumieniowe - przepływ danych wejściowych jest ciągły i jest przetwarzany w czasie rzeczywistym. Nie trzeba czekać na przybycie danych w formie wsadowej.
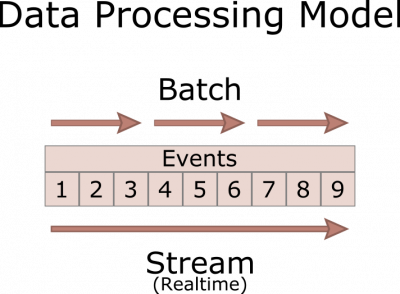
Przetwarzanie wsadowe ma tę zaletę, że jest w stanie przeprowadzić dogłębną analizę, w tym uczenie maszynowe, a jego wadą jest duże opóźnienie.
Przetwarzanie strumienia ma tę zaletę, że ma małe opóźnienie, a wadą jest możliwość wykonania tylko prostej analizy, takiej jak obliczanie wartości średnich w oknie czasowym i oznaczanie odchyleń od wartości oczekiwanych.

Przetwarzanie strumieni często wiąże się z wieloma zadaniami na przychodzących seriach danych („strumień danych”), które mogą być wykonywane szeregowo, równolegle lub jedno i drugie.



Mierzy zawartość wody w podłożu (WC), temperature i przewodność elektryczną gleby (EC).

Mierzy wilgotność, temperature, nasłonecznienie, żyzność.
Przekaźnik (Receiver) - otrzymuje za pomocą fal radiowych dane z poszczególnych sensorów i przesyła je dalej do Smartbox’a.
Smartbox - minikomputer, który zbiera i analizuje dane z poszczególnych sensorów umieszczonych na szklarni i przesyła je do chmury lub serwera.

Tysiące sensorów wysyłających dane do serwera.
Dane pochodzą z różnych stref czasowych.
Różne wymagania / alerty zależne od typu uprawy, klienta itp.

Przykład implementacji w języku python
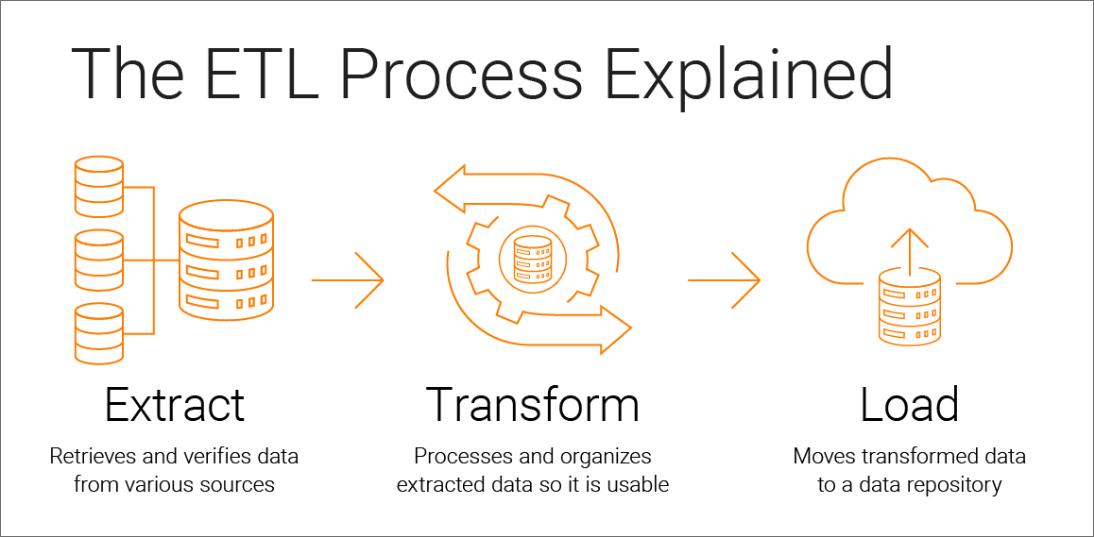
ETL (extract, transform and load) - wyodrębnianie, przekształcanie i zapisywanie, to proces integracji danych, który łączy dane z wielu źródeł danych w jeden, spójny magazyn danych, który jest zapisywany do hurtowni danych lub innego systemu docelowego
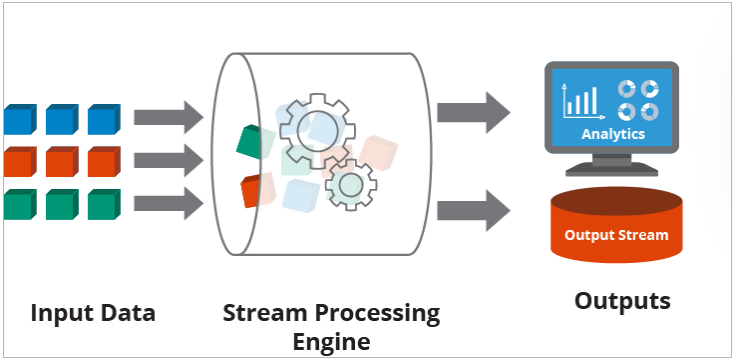
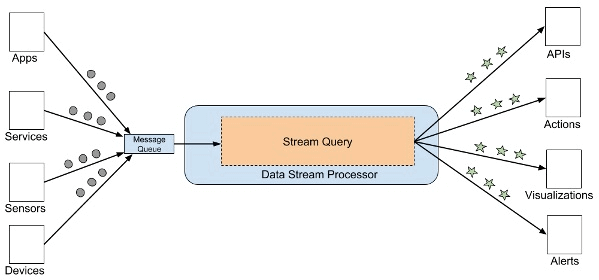
Architektura przetwarzania strumieniowego to struktura komponentów oprogramowania stworzonych do przyjmowania i przetwarzania dużych ilości danych przesyłanych strumieniowo z wielu źródeł jednocześnie.
Niezbędne do przetwarzania strumieniowego jest procesowanie danych. Procesowanie danych to możliwość ciągłego obliczania statystyk podczas poruszania się w strumieniu danych.
Procesowanie danych umożliwia zarządzanie, monitorowanie i analizę danych strumieniowych na żywo w czasie rzeczywistym.
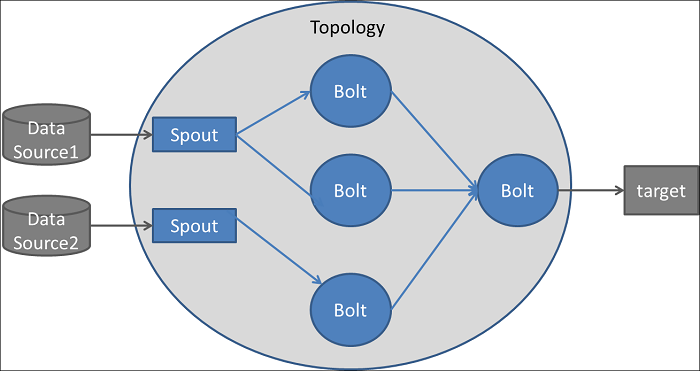
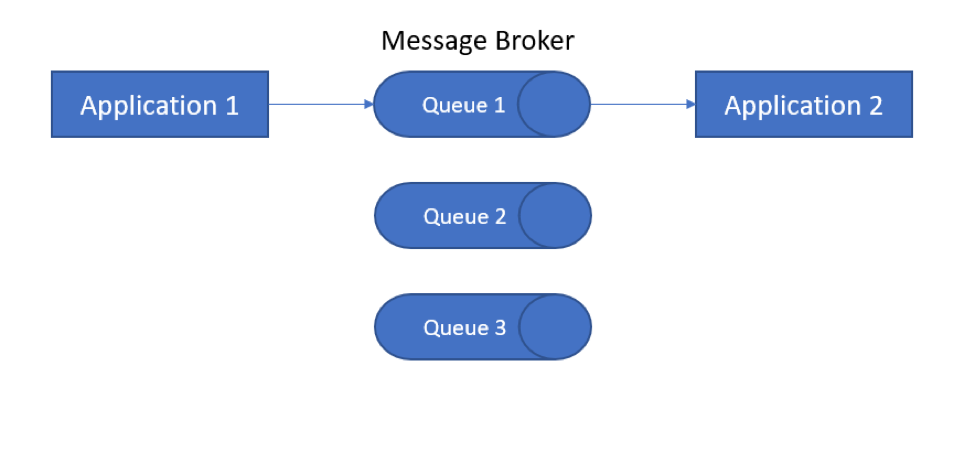
Jest to element, który pobiera dane ze źródła zwanego producentem, tłumaczy je na standardowy format wiadomości i na bieżąco przesyła strumieniowo.
Inne komponenty (konsumenci) mogą następnie nasłuchiwać i wykorzystywać komunikaty przekazywane przez brokera.
Pierwsza generacja brokerów komunikatów, takich jak RabbitMQ i Apache ActiveMQ, opierała się na paradygmacie Message Oriented Middleware (MOM).
Później pojawiły się hiperwydajne platformy przesyłania wiadomości (często nazywane procesorami strumieniowymi), które są bardziej odpowiednie dla paradygmatu przesyłania strumieniowego.
Dwa popularne narzędzia do przetwarzania strumieniowego to Apache Kafka i Amazon Kinesis Data Streams, Google processing cloud, Azure IoT Hub.
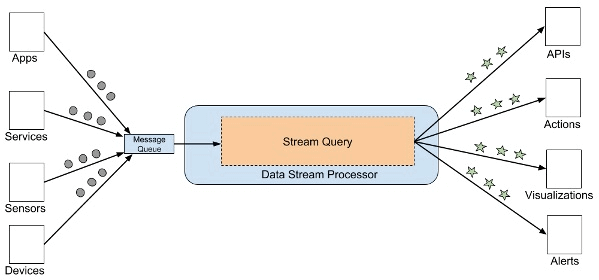
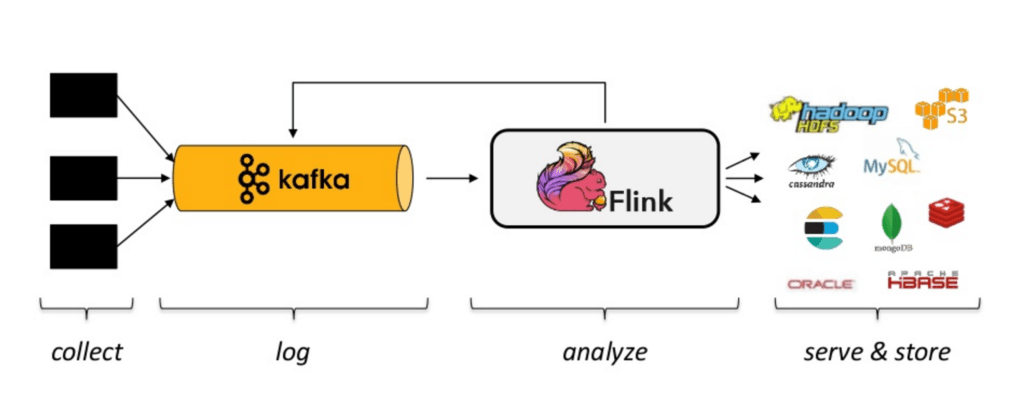
Strumienie danych z brokera komunikatów muszą zostać zagregowane, przekształcone i ustrukturyzowane, zanim dane będą mogły być analizowane za pomocą narzędzi analitycznych opartych na SQL.
Służą do tego narzędzia do procesowania danych strumieniowych, pobierają one zdarzenia z kolejek, a następnie łączą, przekształcają lub agregują dane.
Wynikiem działania processingu może być wywołanie API, akcja, wizualizacja, alert lub w niektórych przypadkach nowy strumień danych.
Data Lake to najbardziej elastyczna i tania opcja przechowywania danych o zdarzeniach, ale jej prawidłowe skonfigurowanie i utrzymanie jest dość trudne.
Schema on-read - tworzenie struktury w danych w momencie odczytu.
Wszyscy dostawcy chmury dostarczają odpowiednie komponenty służące jako jeziora danych.
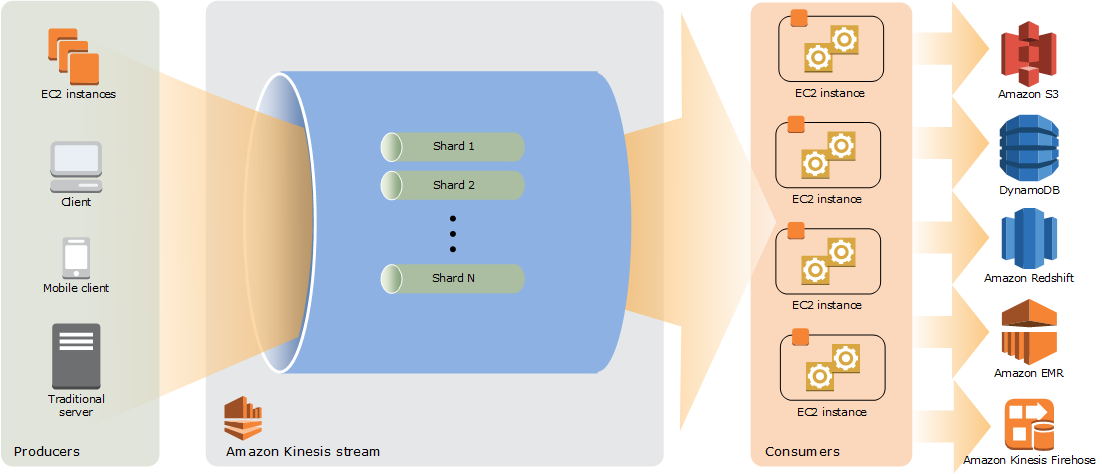
Kinesis Data Streams to usługa przetwarzania, która może nieprzerwanie przechwytywać gigabajty danych na sekundę z setek tysięcy źródeł.
Kinesis Data Analytics może przetwarzać strumienie danych w czasie rzeczywistym za pomocą SQL lub Apache Flink.
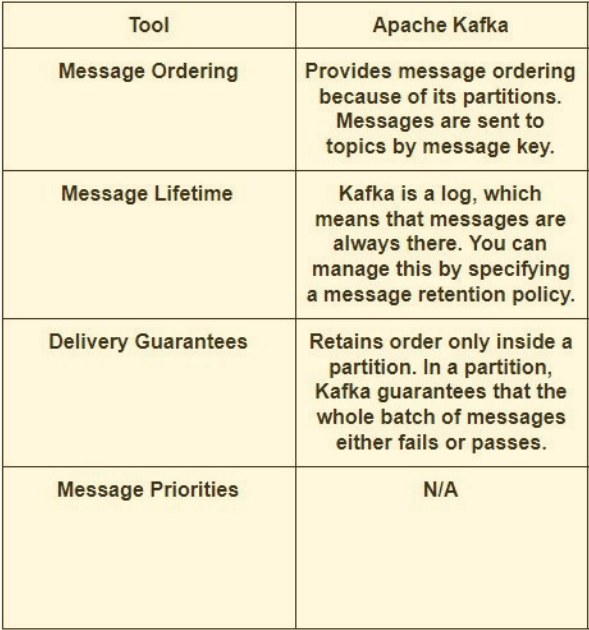
Apache Kafka to otwarta, rozproszona platforma strumieniowania zdarzeń Java/Scala dla wysokowydajnych potoków danych, analizy strumieniowej, integracji danych i aplikacji o znaczeniu krytycznym.
Pierwotnie opracowany przez LinkedIn jako aplikacja kolejki wiadomości, Apache Kafka został udostępniony na zasadach open source i przekazany Apache w 2011 roku. Następnie Kafka przekształcił się w platformę do przesyłania strumieniowego danych o otwartym kodzie źródłowym.
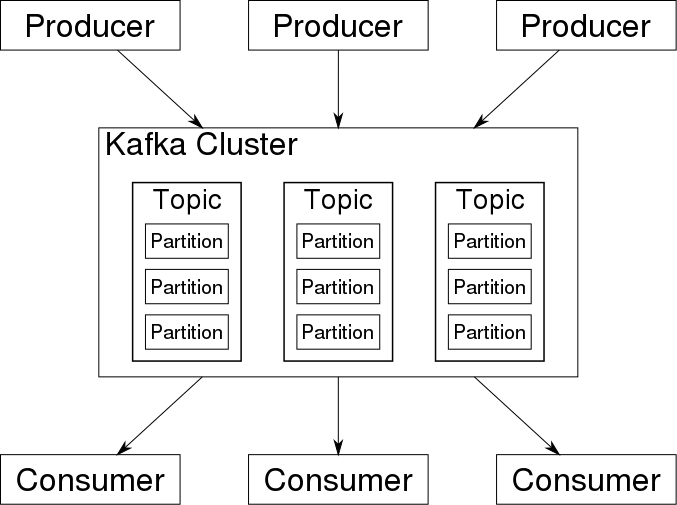
Kafka działa w klastrze w środowisku rozproszonym, które może obejmować wiele centrów danych.
Klaster Kafka składa się z wielu brokerów Kafka (węzłów w klastrze).
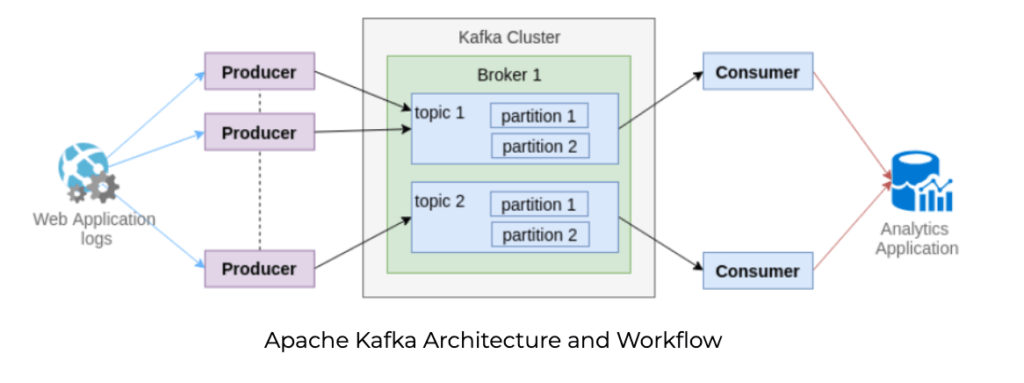
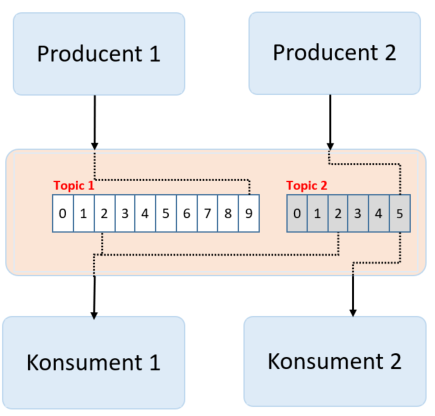
Temat (topic) jest przeznaczony do przechowywania strumieni danych w uporządkowanej i podzielonej na partycje niezmiennej sekwencji rekordów. Każdy temat jest podzielony na wiele partycji, a każdy broker przechowuje jedną lub więcej z tych partycji.
Partycje są replikowanie, czyli ich kopie mogą znajdować się na wielu serwerach.
Kiedy odczytujemy jeden konkretny rekord z pliku, system operacyjny wczytuje kilkaset (lub więcej) następnych rekordów do pamięci operacyjnej.
Aplikacje wysyłają strumienie danych do partycji za pośrednictwem producentów; strumienie danych mogą być następnie wykorzystywane i przetwarzane przez inne aplikacje za pośrednictwem konsumentów.
Wielu producentów i konsumentów może jednocześnie publikować i pobierać wiadomości.
Przygotowanie Apache Kafka zajmuje kilka dni lub tygodni, aby skonfigurować w pełni gotowe środowisko produkcyjne, w oparciu o wiedzę specjalistyczną, którą posiadasz w swoim zespole.
Jako system rozproszony typu open source wymaga własnego klastra, dużej liczby węzłów (brokerów), replikacji i partycji w celu zapewnienia odporności na awarie i wysokiej dostępności systemu.
Konfiguracja klastra Kafka wymaga nauki (jeśli nie ma wcześniejszego doświadczenia w konfigurowaniu i zarządzaniu klastrami Kafka), praktyki inżynierii systemów rozproszonych oraz możliwości zarządzania klastrami, udostępniania, automatycznego skalowania, równoważenia obciążenia, zarządzania konfiguracją i nie tylko.
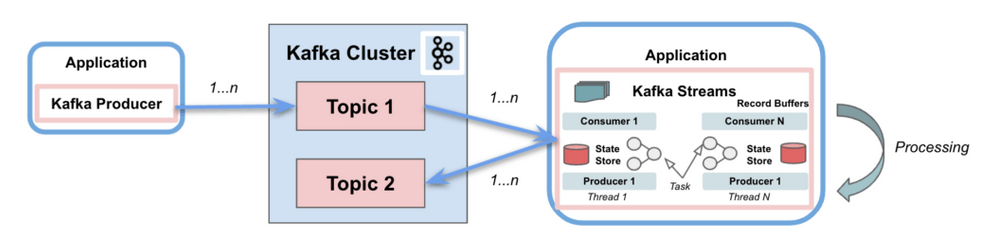
Kafka Streams to interfejs API Java do przetwarzania strumieni dostarczany przez Apache Kafka, który umożliwia programistom dostęp do filtrowania, łączenia, agregowania i grupowania bez konieczności pisania kodu.
Kafka streams jest "natywnym" rozwiązaniem do procesowania danych oferowanym przez Kafkę.
W środowisku przetwarzania strumienia zdarzeń istnieją dwie główne klasy technologii:

Programy dla Apache Flink można pisać w różnych językach, takich jak Python, Scala, SQL i Java. Wreszcie, Flink jest znany z łatwości użytkowania i łatwej integracji z innymi narzędziami do przetwarzania dużych zbiorów danych typu open source, takimi jak Kafka i Hadoop.
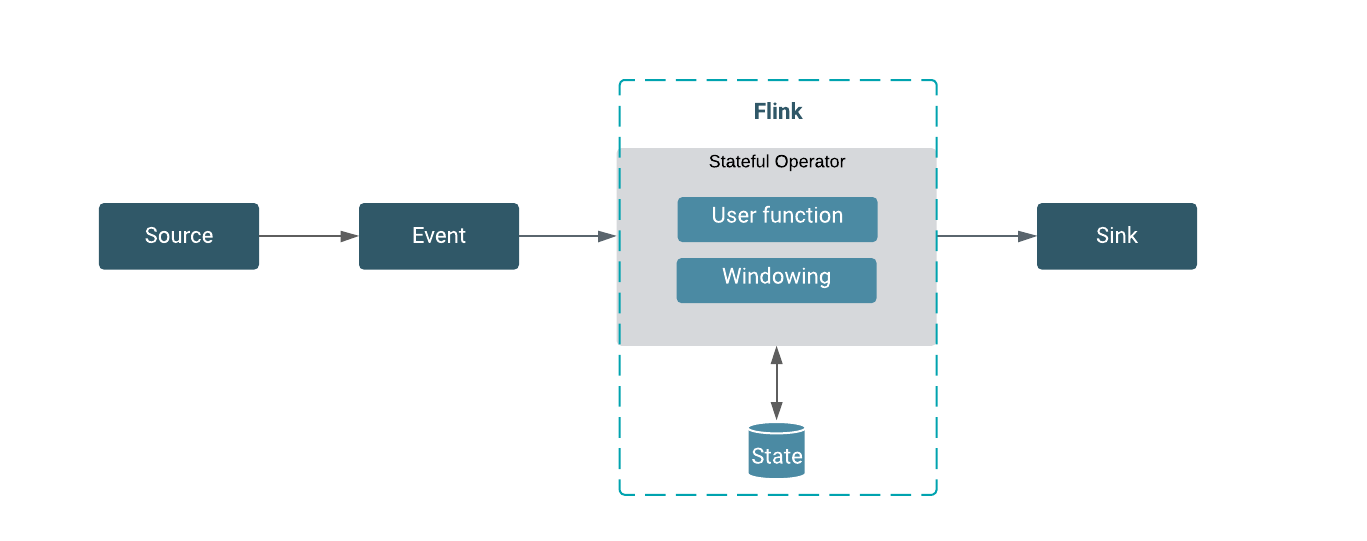
Flink opiera się na koncepcji strumieni i przekształceń. Dane trafiają do systemu przez źródło i wychodzą przez ujście.
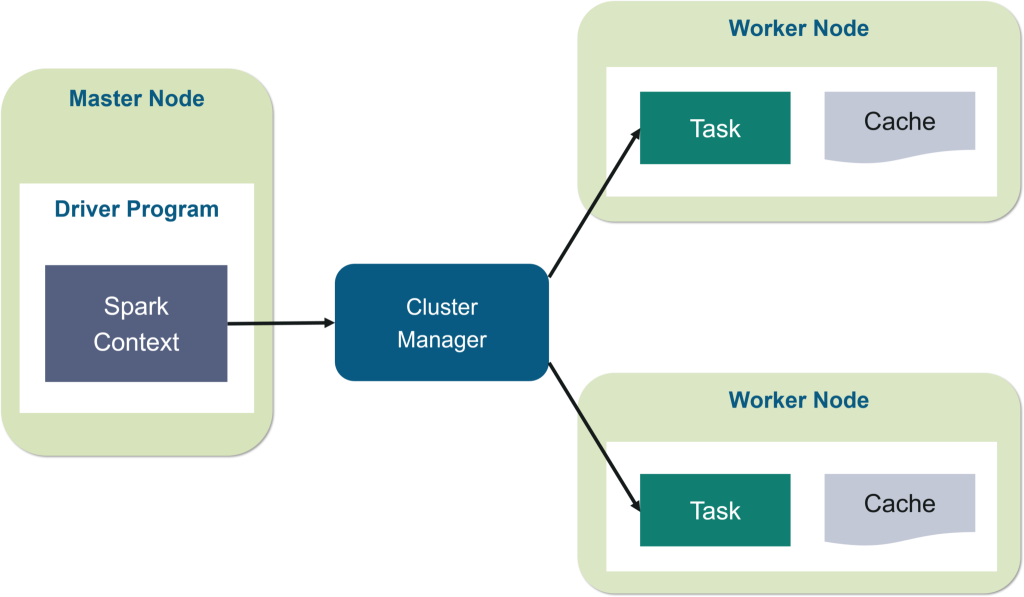
Inną platformą przetwarzania danych typu open source, znaną ze swojej szybkości i łatwości użytkowania, jest Spark.
Ta platforma działa w pamięci RAM w klastrach.
Jedna z wiodących platform przesyłania strumieniowego w czasie rzeczywistym do wszystkiego, od przetwarzania wsadowego i uczenia maszynowego po SQL na dużą skalę i przesyłanie strumieniowe dużych zbiorów danych. W rzeczywistości firmy takie jak Intel, Yahoo, Groupon, Trend Micro i Baidu już polegają na Apache Stream.
Uytkownicy Sparka mogą łatwo pisać aplikacje w Python, SQL, R, Scala lub Java, dzięki czemu są wszechstronne i łatwe w obsłudze.
Storm to to proste rozwiązanie do przetwarzania nieograniczonych strumieni danych big data.
Niektóre z dużych marek korzystających ze Storm to Spotify, Yelp i WebMD.
Jedną z największych zalet Storm jest to, że został zaprojektowany do użytku z dowolnym językiem programowania, oferując użytkownikom dużą elastyczność.
Inne fakty, które warto wiedzieć o Storm, to to, że jest odporny na błędy, skalowalny i łatwo integruje się z technologiami, z których już korzystasz.