Przetwarzanie równoległe i strumieniowe
Uwaga! Kod z którego będziemy korzystać na zajęciach jest dostępny na branchu ApacheFlinkIntroStart w repozytorium https://github.com/WitMar/PRS2020 .
Jeżeli nie widzisz odpowiednich gałęzi na GitHubie wykonaj Ctr+T, a jak to nie pomoże to wybierz z menu Git->Fetch.
Flink
Apache Flink to framework i silnik przetwarzania rozproszonego do obliczeń stanowych na nieograniczonych i ograniczonych strumieniach danych. Flink został zaprojektowany do pracy we wszystkich typowych środowiskach klastrowych, wykonując obliczenia w pamięci, z dużą prędkością i w dowolnej skali.
Flink umożliwia przetwarzanie danych w modelu batchowym (gdy wszystkie dane są dostępne przy uruchomieniu przetwarzania - strumień ograniczony) oraz strumieniowe, w którym dane są ciagle dodawane a obliczenia i agregacje są zwykle wywoływane w oknach czasowych (strumień nieograniczony).
Uruchomienie
Uwaga! Na zajęciach musisz korzystać z systemu LINUX!
Flink działa na wszystkich środowiskach podobnych do UNIX, tj. Linux, Mac OS X i Cygwin (dla Windows). Aby uruchomić Flinka musisz mieć zainstalowaną Javę 11.
Krok 1: Pobierz najnowszą wersję binarną Flink, my skorzystamy z wersji 1.15
, następnie wypakuj do lokalnego folderu (na wydziale polecamy wypakować na dysku POLIGON).
Struktura katalogów Flinka:
bin/ zawiera plik binarny flink, a także kilka skryptów bash, które zarządzają różnymi zadaniami i zadaniamiconf/ zawiera pliki konfiguracyjne, w tym flink-conf.yamlexample/ zawiera przykładowe aplikacje napisane z wykorzystaniem Flink
Aby uruchomić lokalny klaster, uruchom skrypt bash dołączony do Flink:
./bin/start-cluster.shPowinieneś być w stanie przejść do interfejsu internetowego pod adresem localhost:8081, aby wyświetlić pulpit nawigacyjny Flink i sprawdzić, czy klaster jest uruchomiony i działa.
Aby szybko zatrzymać klaster i wszystkie działające komponenty, możesz użyć dostarczonego skryptu:
./bin/stop-cluster.shFlink dostarcza narzędzie CLI, bin/flink, które może uruchamiać programy spakowane jako archiwa Java (JAR) i kontrolować ich wykonywanie. Przesłanie zadania oznacza przesłanie pliku JAR zadania i powiązanych zależności do działającego klastra Flink i wykonanie go.
Aby wdrożyć przykładowe zadanie liczenia słów w działającym klastrze, wydaj następujące polecenie:
./bin/flink run examples/streaming/WordCount.jardla zadań napisanych w języku Python możesz wykonać:
bin/flink run -py examples/python/table/word_count.pyby przekierować wynik do katalogu wykonaj
bin/flink run -py examples/python/table/word_count.py --output wynikMożesz dodatkowo zweryfikować dane wyjściowe, przeglądając logi:
tail log/flink-*-taskexecutor-*.outFlink cluster
Środowisko wykonawcze Flink składa się z dwóch typów procesów: JobManagera i jednego lub więcej TaskManagerów.

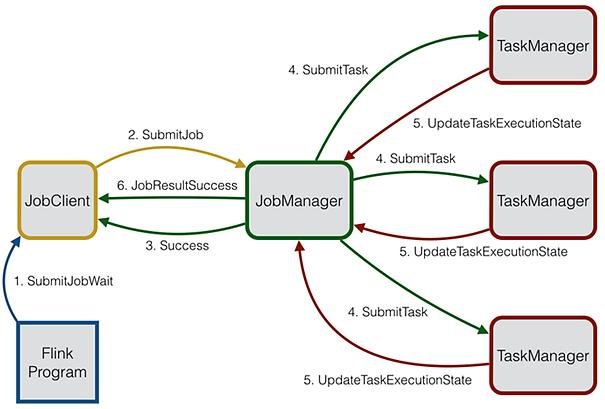
Klient nie jest częścią środowiska wykonawczego i wykonywania programu, ale służy do przygotowania i wysłania zadań do JobManagera. Następnie klient może się rozłączyć (tryb detached) lub pozostać w kontakcie, aby otrzymywać raporty o postępach (tryb atached).
JobManager i TaskManagers mogą być uruchamiane na różne sposoby: bezpośrednio na maszynach jako samodzielny klaster, w kontenerach lub zarządzane przez struktury zasobów.
JobManager
JobManager otrzymuje JobGraph, który jest reprezentacją przepływu danych składającą się z operatorów (JobVertex) i wyników pośrednich (IntermediateDataSet). JobManager przekształca JobGraph w ExecutionGraph. ExecutionGraph jest równoległą wersją JobGraph: dla każdego JobVertex zawiera ExecutionVertex na równoległe podzadanie. Operator z równoległością 100 będzie miał jeden JobVertex i 100 ExecutionVertices.
Zadanie Flink jest najpierw w stanie created, następnie przełącza się na running, a po zakończeniu całej pracy przełącza się na finished. W przypadku niepowodzenia zadanie najpierw przełącza się na failing, w którym anuluje wszystkie uruchomione zadania. Jeśli wszystkie wierzchołki zadania osiągnęły stan końcowy, a zadania nie można zrestartować, zadanie przechodzi na failed. Jeśli zadanie można zrestartować, przejdzie w stan ponownego uruchomienia. Gdy zadanie zostanie całkowicie zrestartowane, osiągnie na nowo stan created.
JobManager ma szereg obowiązków związanych z koordynacją rozproszonego wykonywania Aplikacji Flink: decyduje, kiedy zaplanować następne zadanie (lub zestaw zadań), reaguje na zakończone zadania lub niepowodzenia wykonania, koordynuje punkty kontrolne i koordynuje odzyskiwanie po awariach. Ten proces składa się z trzech różnych elementów:
Menedżer zasobów jest odpowiedzialny za de/alokację zasobów i przydzielanie ich w klastrze Flink.Scheduler zapewnia interfejs REST do przesyłania aplikacji Flink do wykonania i uruchamia nowy JobMaster dla każdego przesłanego zadania. Uruchamia również Flink WebUI, aby dostarczać informacji o wykonywaniu zadań.JobMaster jest odpowiedzialny za zarządzanie wykonaniem pojedynczego JobGraph. Wiele zadań może działać jednocześnie w klastrze Flink, z których każde ma swój własny JobMaster.
Zawsze jest co najmniej jeden JobManager. Zaawansowana konfiguracja może mieć wielu menedżerów zadań, z których jeden jest zawsze liderem, a pozostali sie mu podporządkowują.
Task Manager
Menedżerowie zadań (nazywani również workerami) wykonują zadania przepływu danych oraz buforują i wymieniają strumienie danych.
Zasoby wykonawcze w Flink są definiowane za pomocą Slotów zadań. Każdy TaskManager ma jeden lub więcej slotów zadań, z których każdy może uruchamiać jeden potok równoległych zadań.
Zawsze musi istnieć co najmniej jeden menedżer zadań. Najmniejszą jednostką planowania zasobów w Menedżerze zadań jest miejsce na zadania. Liczba przedziałów zadań w Menedżerze zadań wskazuje liczbę jednoczesnych zadań przetwarzania.
Task Slots
Każdy proces roboczy (TaskManager) jest procesem JVM i może wykonywać jedno lub więcej podzadań w osobnych wątkach. Aby kontrolować, ile zadań akceptuje TaskManager, ma on tak zwane sloty zadań (przynajmniej jeden).
Każdy slot zadań reprezentuje stały podzbiór zasobów TaskManagera. Na przykład TaskManager z trzema gniazdami przeznaczy 1/3 swojej zarządzanej pamięci na każdy slot. Rozmieszczenie zasobów oznacza, że podzadanie nie będzie konkurować z podzadaniami innych zadań o pamięć zarządzaną, ale zamiast tego ma pewną ilość zarezerwowanej pamięci zarządzanej. Zwróć uwagę, że nie występuje tutaj izolacja procesora; obecnie sloty oddzielają tylko zarządzaną pamięć zadań.
Dostosowując liczbę przedziałów zadań, użytkownicy mogą określić, w jaki sposób podzadania są od siebie odizolowane. Posiadanie jednego gniazda na menedżera zadań oznacza, że każda grupa zadań działa w oddzielnej maszynie wirtualnej (którą można na przykład uruchomić w osobnym kontenerze). Posiadanie wielu gniazd oznacza, że więcej podzadań współużytkuje tę samą maszynę JVM.
PyFlink
PyFlink to interfejs API języka Python dla Apache Flink, który umożliwia tworzenie skalowalnych obliczeń wsadowych i strumieniowych, takich jak potoki przetwarzania danych w czasie rzeczywistym, eksploracyjna analiza danych na dużą skalę, potoki uczenia maszynowego (ML) i procesy ETL.
PyFlink jest dostępny w PyPi i można go zainstalować w następujący sposób:
python -m pip install apache-flink==1.15.0Aby uruchamiać programy w PyCharm. Otwórz PyCharm. Wejdź w File->Settings->Interpreter. Wybierz koło zębate i add a następnie wybierz System interpreter.
Python intrefaces
PyFlink umożliwia użytkownikom tworzenie zadań Flink w Pythonie. Flink udostępnia trzy typy interfejsów API: API SQL, API tabel oraz API DataStream. Pierwsze dwa to stosunkowo podstawowe interfejsy API. Interfejs API table PyFlink umożliwia pisanie zapytań relacyjnych w sposób podobny do używania SQL lub pracy z danymi tabelarycznymi w Pythonie. Table API jest bardziej ogólnym interfejsem API niż SQL. W przypadku zadań opracowanych w oparciu o API tabel, logika jest wykonywana po serii optymalizacji po stronie serwera.
Interfejs API PyFlink DataStream zapewnia kontrolę na niższym poziomie nad podstawowymi blokami konstrukcyjnymi Flink, stanem i czasem, w celu tworzenia bardziej złożonych przypadków użycia przetwarzania strumieniowego.
SQL interface
Pozwala wykorzystywać standardowy SQL do wykonywania zapytań na danych.
Python Table API
Python Table API umożliwia użytkownikom procesowanie danych poprzez wykorzystanie metod funkcyjnych jak select(), group_by(), where() które są automatycznie tłumaczone na niskopoziomowe metody.
Oba interfejsy Table API oraz SQL korzystają ze wspólnego modelu danych, którym są tabele. Wyrażenia na tablicach są "lazy evaluated" (czyli operacje w strumieniu wykonywane są dopiero w momencie, gdy dane są nam potrzebne na wyjściu).
Wejściowym obiektem na którym będziemy pracować będzie tzw. "TableEnvironment". W ramach tego środowiska będziemy rejestrować tabele i źródła danych, wykonywać zapytania oraz uruchamiać dedykowane funkcje.
EnvironmentSettings oraz TableEnvironment z modułu pyflink.table będą wykorzystywane do tworzenia TableEnvironment dla zadań batchowych.
TableEnvironment
Żeby utworzyć zadanie we Flink musimy utworzyć "środowisko" tabel. Do wyboru mamy dwie opcje przetwarzanie batchowe i strumieniowe. Na tych zajęciach skupimy się na przetwarzaniu batchowym (wsadowym).
env_settings = EnvironmentSettings.in_batch_mode()
table = TableEnvironment.create(env_settings)Zadanie 1
Zobacz przykłady tworzenia środowiska tabel w pliku TableEnv.py.
Model danych
Tabele służą za źródła danych jak i jako obiekty pośrednie przy transformacji danych. Tabele możemy tworzyć zapisując obiekty na sztywno w kodzie jako kolekcje w Pythonie lub odczytując je ze źródeł takich jak pliki, tabele czy też zewnętrzne systemy (jak Kafka).
Tworzenie tabel na postawie zapisanych na sztywno danych :
Pyflink wspiera użytkowników w tworzeniu tabel źródłowych z podanej listy. Poniższy przykład definiuje tabelę zawierającą trzy wiersze danych: [(Hello, 1), ((world, 2), ((Flink, 3)]), która ma dwie kolumny z nazwami kolumn a i B oraz typami varchar i bigint.
tab = t_env.from_elements([("hello", 1), ("world", 2), ("flink", 3)], ['a', 'b'])Ta metoda jest zwykle używana w fazie testowej, gdyż może szybko utworzyć tabelę źródła danych w celu weryfikacji logiki zadania. Pierwszy parametr służy do określenia listy danych. Każdy element na liście musi być typu krotki; Drugi parametr określa schemat tabeli
Tworzenie tabel za pomocą SQL API.
DDL jest najbardziej zalecanym sposobem definiowania tabel źródeł i ujść danych, a wszystkie konektory obsługiwane w Java Table API & SQL mogą być używane w zadaniach pyflink Table API poprzez DDL. Wśród nich są: Kafka, Upsert Kafka, Firehose, Kinesis, JDBC, Elasticsearch, FileSystem, HBase, DataGen, Print, BlackHole, Hive. Podobnie jak w przypadku tworzenia tabeli źródła danych, można również utworzyć tabelę wynikową za pomocą języka DDL. Wynik przetwarzania możemy zapisywać w plikach, albo przesyłać do zewnętrznych systemów, czy kolejek.
Zadanie 2
Zobacz przykłady tworzenia tabeli z kolekcji w pliku DataSourceExample.py.
Zadanie 3
Zobacz przykłady tworzenia środowiska tabel z pliku CSV w pliku FileSourceCSV.py.
Zadanie 4
Zobacz przykłady tworzenia środowiska tabel źródła danych i ujścia danych z pliku CSV w pliku FileSink.py. Zobacz co stanie się, gdy nie wykonamy wait() po operacji insert.
Wait if necessary for at most the given time (milliseconds) for the data to be ready. For a select operation, this method will wait until the first row can be accessed locally. For an insert operation, this method will wait for the job to finish
Operacje
Operacje na tabelach wykonaywane są funkcyjnie, tabele są niemutowalne, więc wszystkie operacje tworzą, jako wynik działania, nowe kopie tabel, które są następnie dalej przetwarzane w kolejnych krokach.
Projekcje
select - działa jak select w SQL, pozwala nam wybierać kolumny z tabel, dodawać, usuwać kolumny, czy też nadawać im aliasy, albo tworzyć nowe na podstawie istniejących danych.
Dodatkowo możemy na wyniku wykonywać znane operacje z SQL takie jak limit(), czy distinct().
Lista funckji SQL z których możemy korzystać jest dostępna tutaj (w postaci API SQL i Table API) :
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/functions/systemfunctions/
Zadanie 5
Zobacz przykłady selectów w pliku Select.py.
Filtry
where - umożliwia filtrowanie wierzy za pomocą logicznego warunku, podobną rolę spełnia element DataStream api o nazwie filter
Zadanie 6
Zobacz przykłady selectów w pliku Filtering.py.
Join
join - służy do łączenia dwóch tabel w jedną tabelę. Uwaga! Flink nie radzi sobie z konfliktami nazw i w związku z tym nie możemy mieć tej samej nazwy kolumny w obu tabelach!
Zadanie 7
Zobacz przykłady selectów w pliku Join.py.
Aggregacje
group_by - służy do agregacji wierszy i tworzenia podsumowań takich jak średnie, zliczenie (count) czy sumowanie
Zadanie 8
Zobacz przykłady selectów w pliku Aggregations.py.
User defined functions (UDF)
Python Table API to relacyjne API, które pod względem funkcji jest podobne do SQL. Niestandardowe funkcje w SQL są bardzo ważne, ponieważ mogą rozszerzyć zakres, w jakim można użyć SQL. Podobnie funkcje UDF są przeznaczone do opracowywania funkcji niestandardowych w celu rozszerzenia scenariuszy, w których używany jest interfejs API tabel w języku Python. Oprócz zadań Python Table API, Python UDF mogą być również używane w zadaniach Java Table API i SQL.
Istnieje wiele sposobów definiowania Python UDF w PyFlink. Użytkownicy mogą zdefiniować klasę Pythona, która dziedziczy funkcję ScalarFunction lub zdefiniować zwykłą funkcję Pythona lub funkcję Lambda, aby zaimplementować logikę UDF.

Zadanie 9
Zobacz przykład w pliku UserDefined.py.
Plan wykonania zadania
Zadanie 10
Prześlij na serwer zadanie Aggreations_server.py zobacz w GUI jak dzielone jest zadanie i jak wygląda jego wykonanie.
Uwaga! Flink nie obsługuje nagłówków w CSV, zarówno odczytu nagłówka jako osobnej wartości i pomijaniu go przy tworzeniu tabeli jak i możliwości zapisu w ujściu jako pierwszy wiersz. Dlatego też wszystkie dane wejściowe powinny mieć usunięty nagłówek z danych csv, inaczej podczas uruchomienia powstaną błędy.
Przykłady
W pliku word_count.py znajduje się pełne zadanie Flink opracowane w oparciu o Python Table API. Logika zadania polega na odczytaniu pliku, obliczeniu liczby słów i zapisaniu wyników obliczeń do pliku. Wydaje się proste, ale zawiera wszystkie podstawowe procesy tworzenia zadania Python Table API.
Pierwszym krokiem jest zdefiniowanie trybu wykonywania zadania, np. w trybie wsadowym lub strumieniowym, współbieżności i konfiguracji zadania.
Następnym krokiem jest zdefiniowanie tabeli źródłowej i tabeli ujścia. Tabela źródłowa określa, skąd pochodzi źródło danych zadania i jaki jest format danych. Tabela ujścia definiuje, gdzie zapisać wynik wykonania zadania i jaki jest format danych.
Ostatnim krokiem jest zdefiniowanie logiki wykonania zadania, jak obliczanie zapisanej liczby w tym przykładzie.
Dodatkowo w pliku basic_operations.py można znaleźć przykłady podstawowych operacji na prostym modelu danych.
Zadanie 11
Napisz program, który wypisze liczbę państw w podziale na kontynenty
Zadanie 11
Napisz program, który wypisze statystykę liczby państw zaczynających się na dane litery w podziale na kontynenty. Czyli np. A 1 EU A 2 AF .. B 1 EU itp.
- *
Wykorzystano materiały z: