Przetwarzanie równoległe i strumieniowe
Uwaga! Kod z którego będziemy korzystać na zajęciach jest dostępny na branchu thread w repozytorium https://github.com/WitMar/PRS2025 .
Przetwarzanie równoległe
Procesy to zasadniczo programy, które są wykonywane na procesorze. Proces może tworzyć inne procesy, które są znane jako procesy potomne (child processes). Procesy są odizolowane, co oznacza, że nie współdzielą pamięci z żadnym innym procesem.
Wątek to indywidualny segment procesu, co oznacza, że proces może mieć wiele wątków. Wątek ma trzy stany: uruchomiony, gotowy i zablokowany. Wątki współdzielą zasoby (procesor, pamięć, kod) w ramach jednego procesu.
Wątek jest również znany jako lekki proces. Kiedy wiele wątków jest wykonywanych w procesie w tym samym czasie, otrzymujemy termin „wielowątkowość". Na przykład w przeglądarce wiele kart może być różnymi wątkami. MS Word wykorzystuje wiele wątków: jeden wątek do formatowania tekstu, inny wątek do przetwarzania danych wejściowych itp.
Wielowątkowość to model wykonywania programu, który pozwala na tworzenie wielu wykonywanych niezależnie wątków w ramach jednego procesu, które jednocześnie współdzielą zasoby procesu. W zależności od sprzętu wątki mogą działać w pełni równolegle, jeśli są dystrybuowane do osobnych rdzeni procesora lub wirtualnie równolegle gdy to system operacyjny steruje przydziałem zasobów do wątków.
Pomimo wielu zalet przetwarzania wielowątkowego (równoległego) związane jest z nimi zarówno zwiększenie złożoności przetwarzania jak i pare trudnych do rozwiązania błędów. Istnieje kilka typowych scenariuszy, które możesz napotkać w aplikacjach wielowątkowych. Obejmują one:
Problemy z dostępem do danych, w których dwa wątki odczytują i modyfikują te same dane. Bez odpowiedniego wykorzystania mechanizmów blokujących może dojść do niespójności danych.Problemy z brakiem wątków i rywalizacją o zasoby pojawiają się, gdy wiele wątków próbuje uzyskać dostęp do pojedynczego chronionego zasobu.Problemy rożnych ścieżek wywołań w zależności od przydziału zasobów procesora.
Elementy te będą tematem pierwszej części zajęć.
Przetwarzanie strumieniowe
W przeszłości dane były zazwyczaj przetwarzane w partiach na podstawie harmonogramu lub określonego wcześniej progu (np. co noc o 1 w nocy, co sto wierszy lub za każdym razem, gdy wolumen osiąga dwa megabajty). Jednak wraz ze wzrostem liczby danych do przetworzenia okazało się, że przetwarzanie wsadowe (ang. batch processing) nie jest w stanie wydajnie przetwarzać danych.
Przetwarzanie strumieniowe stało się koniecznością w nowoczesnych aplikacjach. Przedsiębiorstwa zwróciły się w stronę technologii, które reagują na dane w czasie ich tworzenia. Przetwarzanie strumieniowe umożliwia aplikacjom reagowanie na nowe zdarzenia w danych (np. przekroczenie zakresu alarmowego) w momencie ich wystąpienia. Zamiast grupować dane i zbierać je w określonych odstępach czasu, aplikacje przetwarzania strumieniowego gromadzą i przetwarzają dane natychmiast po ich wygenerowaniu.
Działania, które przetwarzanie strumieniowe wykonuje na danych, obejmują agregacje (np. obliczenia, takie jak suma, średnia, odchylenie standardowe), analizy (np. przewidywanie przyszłego zdarzenia na podstawie wzorców danych), przekształcenia (np. zmiana liczby na format daty ), wzbogacanie (np. łączenie punktu danych z innymi źródłami danych w celu stworzenia większego kontekstu i znaczenia) oraz przetwarzanie (np. wstawianie danych do bazy danych).
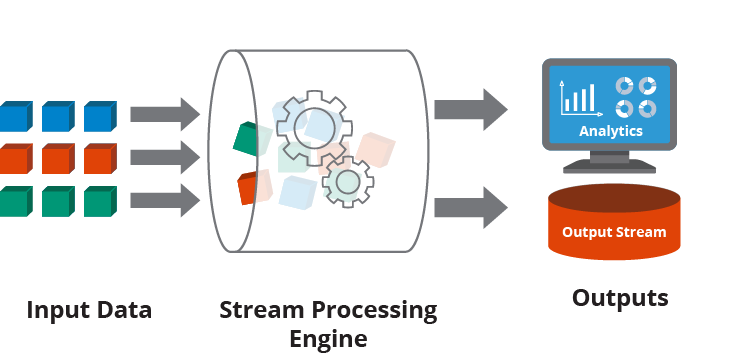
Przetwarzanie strumieni jest najczęściej stosowane do danych generowanych jako seria zdarzeń, takich jak dane z sensorów, systemów przetwarzania płatności oraz logów aplikacji. Typową architekturą wykorzystywaną w tym podejściu jest strategia publisher/subscriber (powszechnie określanego jako pub/sub) lub sink/source. Dane i zdarzenia są generowane przez publishera lub źródło (sink) i dostarczane do aplikacji przetwarzającej strumień będącej subscriberem. Od strony technicznej typowym publisherem jest np. Apache Kafka® a bibliotekami przetwarzającymi dane Apache Spark, Hadoop czy też Apache Flink.
Elementy te będą tematem drugiej części zajęć.
Środowisko develperskie - Java
Edytor
Implementując programy w języku Java, rekomendowanym (i aktualnie jednym z najpopularniejszych) IDE jest IntelliJ IDEA dostępny za darmo w wersji Community (link poniżej) (jako studenci możecie Państwo prosić o darmowy dostęp do wersji Ultimate - https://www.jetbrains.com/community/education/#students):
Repozytorium kodu
Zadanie 1
Załóż konto na GitHub
Otwórz repozytorium
Otwórz Idea intellij na komputerze.
W przypadku, gdy uruchamiasz edytor poraz pierwszy zobaczysz wyskakujące okno i wybierz z niego Project from version control, w przypadku, gdy nie jest to Twoje pierwsze uruchomienie wejdź na File-> New -> Project From Version Control -> Git.
Skopiuj w pokazującym się nowym oknie adres dostępny po wybraniu na stronie GitHub opcji CloneOrDownload (uwaga wybierz adres z opcja HTTPS, adres w opcji SSH nie zadziała!!).
Domyślnie po uruchomieniu znajdujesz się na branchu main, który u nas jest pusty. Wybierz w prawym dolnym rogu aplikacji nazwę brancha i przenieś się na branch thread.
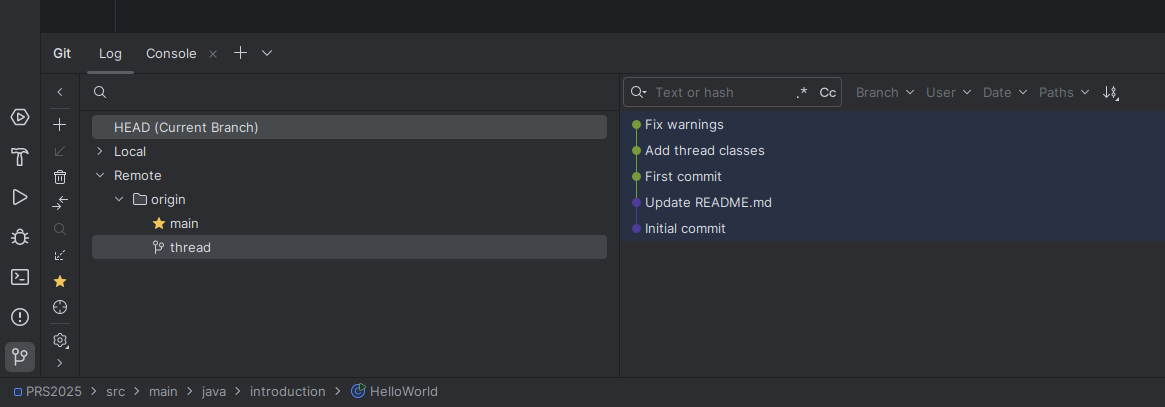
Powinieneś uzyskać następujący efekt - z dokładnością do nazwy klasy. Uwaga jeśli kod nie jest pokolorowany tak jak oczekujesz znaczy to, że środowisko nie rozpoznało automatycznie twojego pliku Mavena:
Wybierz ikonkę lupki i wpisz maven, wybierz opcję Add Maven Project.
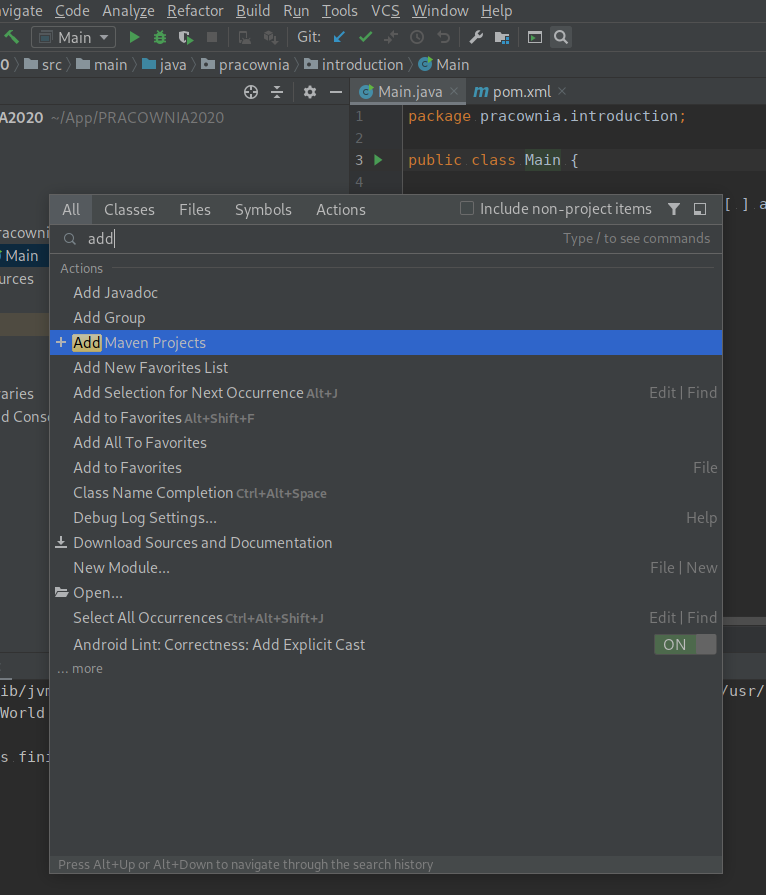
Następnie znajdź katalog do którego ściągnąłeś kod i wybierz plik pom.xml. Powinieneś otrzymać poniższy wynik (spójrz na ikonki przy plikach!).
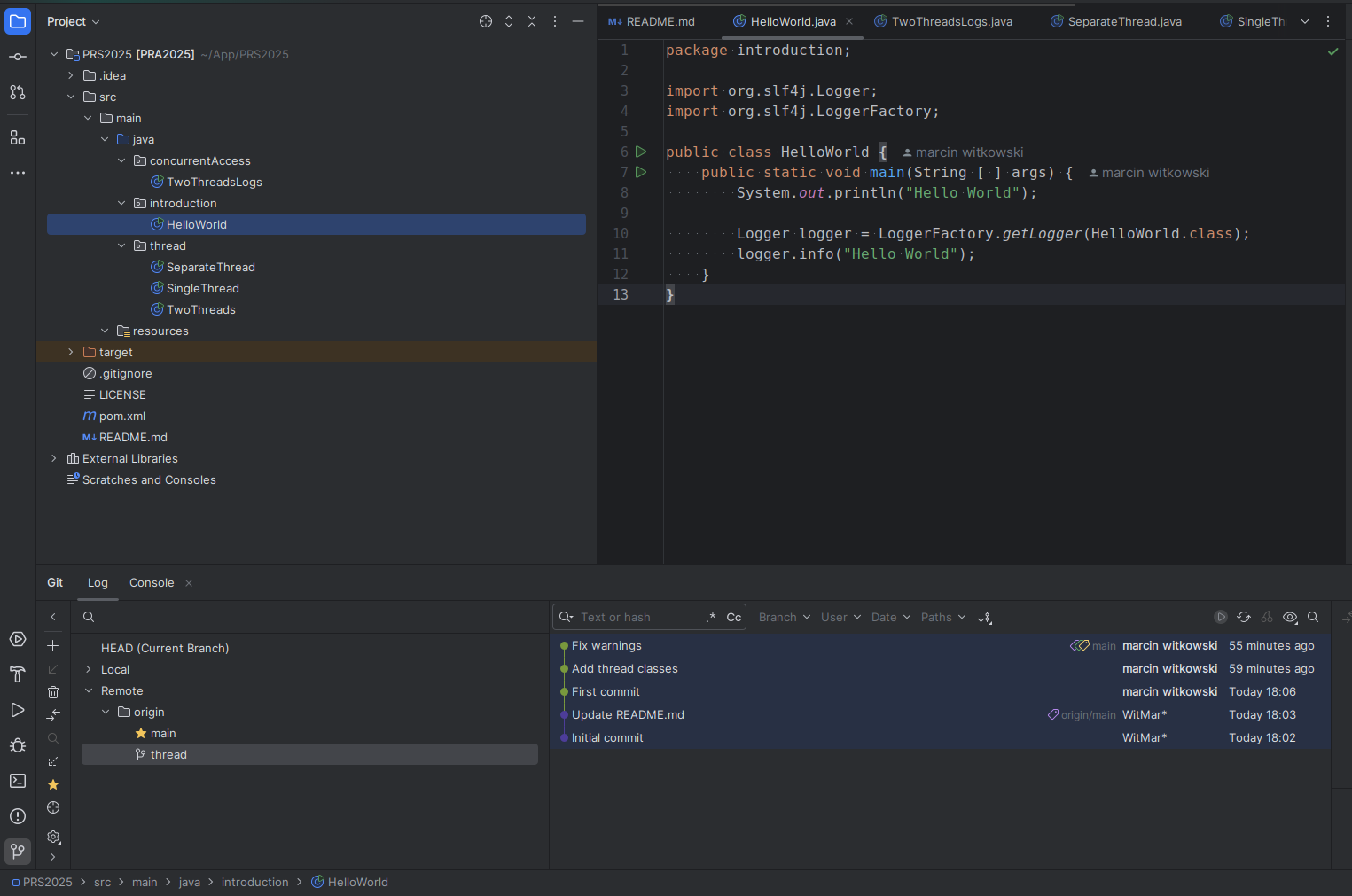
Jeżeli nadal kod nie jest dobrze pokolorowany wejdź w opcje File -> Project Structure, ustaw wersje Javy na 17 w zakładce Project oraz składni w zakładce Module też na java 17.
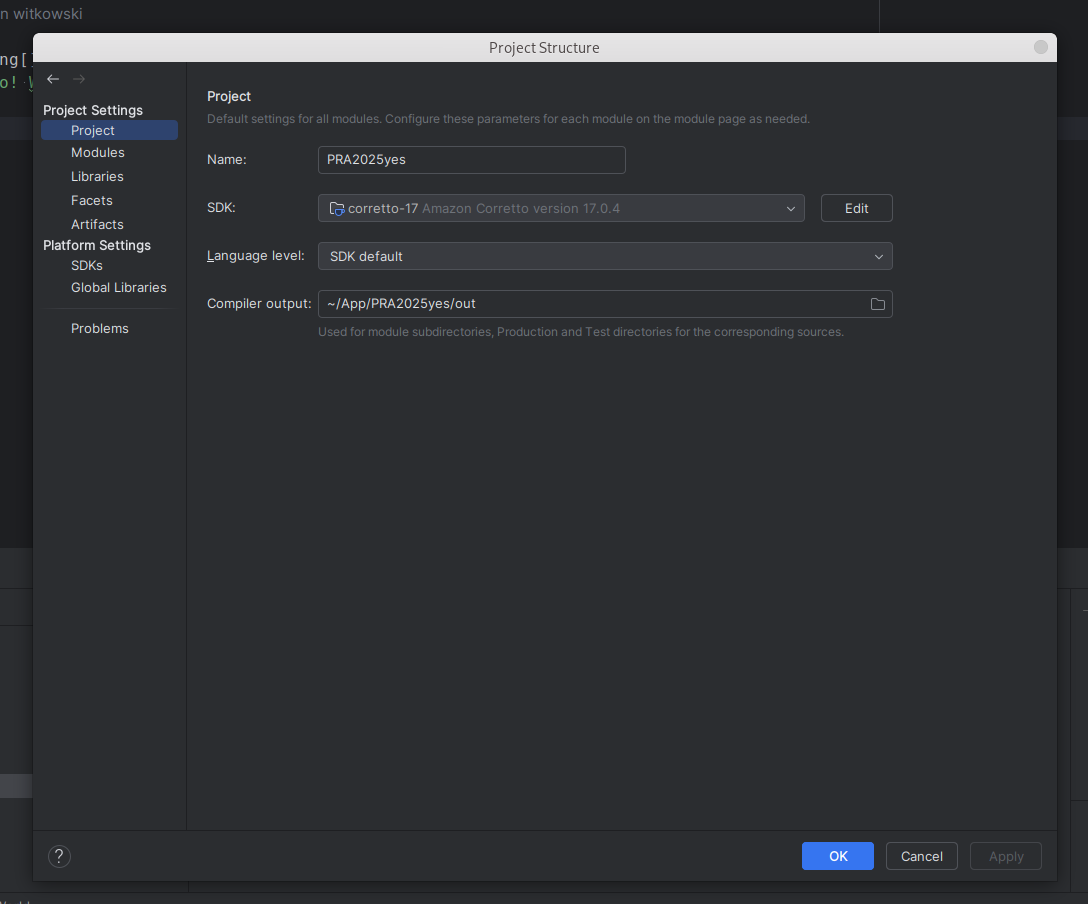
Sprawdź wersje kompilatora używanego przez IDE File -> settings -> compiler, też wybierz wersję Java 17.
Maven
Maven to system budowania aplikacji, który pomaga nam zautomatyzować proces kompilacji i generowania plików uruchomieniowych jar-ów, war-ów itp. Narzuca on specyficzną strukturę projektu.
* pom.xml – główny plik konfiguracji Maven* /src/main – katalog, gdzie znajdziemy pliki naszego programu, są tam dwa podkatalogi: java – tutaj trafiają wszystkie klasy (cały kod naszego modułu)* resources – tutaj będą wszystkie pliki, które nie są kodem, np. grafiki, pliki XML, konfiguracje w przypadku projektów webowych będziemy mieli także katalog webapp, który jest używany do umieszczania wszystkich treści webowych* /src/test - ma podobną strukturę jak katalog main z tą różnicą, że jest on wykorzystywany tylko w trakcie automatycznych testów* /target – tutaj trafia skompilowany projekt (czyli np. w postaci wykonywalnego pliku JAR lub aplikacji webowej WAR)
Po rozwinięciu powinniśmy widzieć listę instrukcji (jeżeli nie wybieramy odśwież - dwie zielone strzałki, jak nie pomoże klikamy plusik i wskazujemy na plik pom.xml w naszym projekcie i ok).
Po tym etapie plik Main.java powinien mieć obok nazwy klasy zielone kółeczko z "c" w środku, jeżeli tak nie jest najlepiej powtórz wszystkie operacje od początku.
Więcej o Mavenie można znaleźć np tutaj:
Maven dokumentacja:
Thread
W języku Java klasy posiadające statyczną metodę main() mogą być uruchamiane. Domyślnie uruchomienie metody main tworzy tzw. główny wątek (ang. main), który uruchamia kod się w niej znajdujący.
Wejdź do klasy SingleThread i uruchom ją. Wywołanie wątku możemy zastopować stosując metodę sleep i podając w nawiasie liczbę milisekund na którą chcemy zatrzymać wątek.
Thread.sleep(500);W momencie zastopowania wątek może przekazać swoje zasoby, takie jak procesor do innego wątku.
W przypadku, gdy wątek jest w stanie nie pozwalającym mu na wykonanie metody sleep może zwrócić wyjątek (exception). Stąd kompilator wymusza na nas otoczenie tej operacji poprzez operacje try catch obsługujące pojawiające się wyjątki.
W przypadku gdy chcemy uruchomić więcej niż jeden wątek w kodzie Javy najprosciej jest wyłączyć implementację wątku do osobnej klasy. Dokonaliśmy tego w klasie SeparateThread poprzez dodanie podklasy, która dziedziczy z klasy Thread. Klasa Thread posiada wiele metod do zarządzania wątkami o których powiemy sobie później. Teraz interesuje nas metoda run() w której umieszczamy kod do wywołania przez wątek. W celu wykonania własnego kodu nadpiszemy tę metodę nadklasy w naszej klasie poprzez definicję metody o tej samej nazwie i wskazując adnotacją @Override, że jest to nadpisanie metody.
class Concurrency extends Thread {
@Override // override method from superclass
public void run() {}
}Możemy teraz w głównej metodzie utworzyć obiekt klasy Concurrency, każdy taki obiekt jest wątkiem, który możemy uruchomić poprzez wykonanie metody start().
Żeby odnaleźć się w tym w którym wątku się obecnie znajduje wykonanie kodu możemy skorzystać ze statycznej metody klasy Thread wypisującej nazwę wątku.
Thread.currentThread().getName()Zadanie 2
Uruchom klasę SeparateThread.java, zaobserwuj jak działają dwa wątki, główny i wywołany przez nasz program. Dodaj operacje wypisania czegoś na ekran do głównego wątku, kiedy się ona wywoła?
Przypadek, gdy chcielibyśmy utworzyć więcej wątków z klasy Concurrency pokazany jest w klasie TwoThreads.
Zadanie 3
Uruchom klasę TwoThreads.java, zaobserwuj jak działają dwa wątki operujące na osobnych danych. Czy jest jakaś reguła w tym jak wywoływane są wątki i jak dzielony jest procesor?
Logger
Metoda System.out.printl jest synchronizowana to znaczy, że dostęp do niej ma tylko jeden wątek na raz (o czym będziemy mówić na kolejnych zajęciach). W przypadku dużego obciążenia systemu i dużej liczby wywołań może to bardzo spowalniać i obciążać aplikację. Jednocześnie wiemy jak ważnym i pomocnym elementem projektu informatycznego jest logowanie komunikatów / śledzenie wywołań. Z pomocą przychodzą nam specjalne biblioteki zwane logerami. Szczególnie użyteczne właściwości logerów to: dzielenia logów na poziomy, zapisywanie automatyczne do pliku, a także asynchroniczne wywołanie.
Przykładem biblioteki API do logowania jest slf4j.
Aby używać w naszym projekcie biblioteki slf4j dodaliśmy do naszego projektu (do pliku mavena pom.xml) zależność do biblioteki logowania slf4j wklejając tam:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.16</version>
</dependency>W ogólności jeżeli chcemy dodać bibliotekę slf4j do projektu, aby znaleźć odpowiedni wpis wystarczy w google wpisać maven slf4j. Pierwszy link powinien zaprowadzić nas na stronę:
Po wyborze wersji zobaczymy wpis:
Uwaga! Na każdych zajęciach potrzebne zależności będą już dodane do ustawień mavena.
Dodaliśmy do klasy TwoThreads.java wywołanie loggera poprzez dodanie zmiennej globalnej:
Logger logger = LoggerFactory.getLogger(HelloWorld.class);Uwaga! Dodając nowy obiekt zwróć uwagę, że korzystać z biblioteki slf4j, gdyż w Javie jest wiele bibliotek o nazwie Logger, i wykorzystanie innej nie zadziała tak jak chcemy. Innymi słowy spójrz czy w powstałym imporcie w nazwie klasy jest slf4j.
Współdzielenie zasobów
W klasie TwoThreadsLogs.java mamy też przykład programu, w którym dwa wątki współdzielą zasób jakim jest zmienna i. Zobacz jakie anomalie możesz zaobserwować w działaniu takiego programu.
Jeżeli chcielibyśmy połączyć dwie operacje np. inkrementację wartości zmiennej i oraz wypisanie drugiego logu możemy to wykonać poprzed dodanie synchronizowanego bloku kodu.
Dodaj do klasy zmienną globalną
public static Long synchronizer = 0L;oraz synchronizowany blok
synchronized (synchronizer) {
i = i + 1;
log.info("Loop " + this.loopNum + ", Write: " + i);
}Zadanie 5
Uruchom ponownie klasę TwoThreadsLogs.java. Jakie różnice w działaniu zaobserowałeś/łaś.
https://www.koderhq.com/tutorial/java/concurrency/
https://www.geeksforgeeks.org/introduction-of-process-management/?ref=lbp
https://totalview.io/blog/multithreading-multithreaded-applications