Przetwarzanie równoległe i strumieniowe
Apache Flink - okna
Uwaga! Kod z przykładami znajduje się na gałęzi FlinkOkna w repozytorium https://github.com/WitMar/PRS2025 .
Window - okna czasowe
Okna są sercem przetwarzania strumieni danych. Pozwalają one wydzielić fragment danych ze strumienia i zastosować do nich wybrane obliczenia jak agreacje pomiarów w ostatnich 15 minutach, liczbę stanów alarmowych w ostatnich X odczytach itp. Okna możemy definiować dla strumieni z kluczem jak i strumieni bez klucza. Przykłay i obowiązkowe elementy definicji okna przedstawiono poniżej (polecenia w nawiasach kwadratowych ([…]) są opcjonalne):
Keyed windows:
stream
.key_by(...)
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.allowed_lateness(...)] <- optional: "lateness" (else zero)
[.side_output_late_data(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.get_side_output(...)] <- optional: "output tag"Non-keyed windows:
stream
.window_all(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.allowed_lateness(...)] <- optional: "lateness" (else zero)
[.side_output_late_data(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.get_side_output(...)] <- optional: "output tag"Jak widać jedyną różnicą w definicji jest zastosowanie window() albo window_all().
Posiadanie strumienia z kluczem umożliwi równoległe wykonywanie obliczeń w oknie przez wiele zadań, ponieważ każdy strumień z kluczem logicznym może być przetwarzany niezależnie od pozostałych. Wszystkie elementy odnoszące się do tego samego klucza zostaną wysłane do tego samego zadania równoległego. W przypadku strumieni bez klucza oryginalny strumień nie zostanie podzielony na wiele strumieni logicznych, a cała logika okienkowania będzie wykonywana przez jedno zadanie, tj. z równoległością 1.
Możliwe, że niektóre elementy naruszą warunek znaku wodnego, co oznacza, że nawet po wystąpieniu znaku wodnego(t) pojawi się więcej elementów ze znacznikiem czasu t’ <= t. W rzeczywistości w wielu rzeczywistych konfiguracjach niektóre elementy mogą być dowolnie opóźniane, co uniemożliwia określenie czasu, w którym wystąpią wszystkie elementy określonego znacznika czasu zdarzenia. Ponadto, nawet jeśli opóźnienie można ograniczyć, zbyt duże opóźnienie znaków wodnych jest często niepożądane, ponieważ powoduje zbyt duże opóźnienie w ocenie okien czasowych zdarzenia.
Z tego powodu programy do przesyłania strumieniowego mogą wyraźnie oczekiwać pewnych późnych elementów. Spóźnione elementy to elementy, które pojawiają się po tym, jak zegar czasu zdarzenia systemowego (co sygnalizują znaki wodne) minął już czas znacznika czasu spóźnionego elementu.
Okno jest tworzone, gdy tylko pojawi się pierwszy element, który powinien należeć do tego okna, a okno jest całkowicie usuwane, gdy czas (zdarzenie lub czas przetwarzania) przekroczy znacznik czasu zakończenia plus określone przez użytkownika dozwolone opóźnienie. Na przykład w przypadku strategii tworzenia okien opartej na czasie zdarzenia, która tworzy nienakładające się okna co 5 minut i ma dozwolone opóźnienie wynoszące 1 minutę, Flink utworzy nowe okno dla przedziału między 12:00 a 12:05, gdy nadejdzie pierwszy element ze znacznikiem czasu mieszczącym się w tym przedziale, i usunie go, gdy znak wodny przekroczy znacznik czasu 12:06.
Event time vs Processing time
Odnosząc się do czasu w programie do przesyłania strumieniowego (na przykład w celu zdefiniowania okien), można odnieść się do różnych pojęć czasu:
Procesing time - czas przetwarzania: Czas przetwarzania odnosi się do czasu systemowego maszyny, która wykonuje odpowiednią operację. Gdy program do przesyłania strumieniowego działa w czasie przetwarzania, wszystkie operacje oparte na czasie (takie jak okna czasowe) będą korzystać z zegara systemowego maszyn obsługujących danego operatora. Godzinowe okno czasu przetwarzania będzie obejmowało wszystkie rekordy, które dotarły do określonego operatora między godzinami, w których zegar systemowy wskazywał pełną godzinę. Na przykład, jeśli aplikacja zaczyna działać o godzinie 9:15, pierwsze godzinne okno czasowe przetwarzania będzie obejmowało zdarzenia przetwarzane między 9:15 a 10:00, następne okno będzie zawierało zdarzenia przetwarzane między 10:00 a 11:00, i tak NA.
Czas przetwarzania jest najprostszym pojęciem czasu i nie wymaga koordynacji między strumieniami a maszynami. Zapewnia najlepszą wydajność i najniższe opóźnienia. Jednak w środowiskach rozproszonych i asynchronicznych czas przetwarzania nie zapewnia determinizmu, ponieważ jest podatny na prędkość napływania i procesowania rekordów.
Event time - czas zdarzenia to czas, w którym każde pojedyncze zdarzenie wystąpiło u jeo źródła. Ten czas jest zwykle osadzony w rekordach przed wejściem do Flink, a znacznik czasu zdarzenia można wyodrębnić z przychodzącego rekordu. Progra musi określać sposób generowania Watermark, który jest mechanizmem sygnalizującym postęp w odbiorze zdarzeń.
W idealnym świecie przetwarzanie zdarzeń w czasie dawałoby całkowicie spójne i deterministyczne wyniki, niezależnie od tego, kiedy nadejdzie zdarzenie lub w jakiej kolejności. Jeśli jednak zdarzenia nie przychodzą w kolejności (według sygnatury czasowej), przetwarzanie czasu zdarzenia wiąże się z pewnym opóźnieniem podczas oczekiwania na zdarzenia poza kolejnością. Ponieważ można czekać tylko przez skończony okres czasu, nakłada to ograniczenie na to, jak deterministyczne mogą być aplikacje związane z czasem zdarzenia.
Watermark
W przetwarzaniu strumieniowym ważnym elemenetem jest czas wystąpienia zdarzenia. Dla każdego zdarzenia powinniśmy podać jak odczytać czas wystąpienia zdarzenia (jako element przychodzących danych, czas przyjścia, lub inna metoda). Flink umie procesować zdarzenia nawet gdy nie przychodzą w kolejności wystąpienia. Żeby jednak było to możliwe wykorzystuje on mechanizm tzw. watermark. Służy on do określania granicy po wystąpieniu której wiemy, że zdarzenia o znaczniku czasu mniejszym niż t nie przyjdą już jako dane wejściowe (albo że możemy je pominąć w przetwarzaniu).
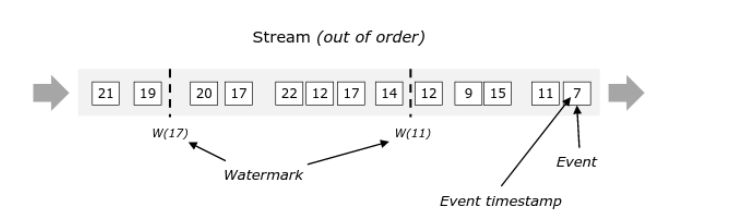
Przykład definicji strategii watermark wykorzystujac standardowe funkcje Flinka został podany poniżej:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import java.time.Duration;
WatermarkStrategy<Tuple2<Long, ?>> watermarkStrategy = WatermarkStrategy
.<Tuple2<Long, ?>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<Long, ?>>() {
@Override
public long extractTimestamp(Tuple2<Long, ?> element, long recordTimestamp) {
return element.f0; // assumes timestamp is in the first field
}
});Ustawienia watermark możemy stosować albo dla żródła danych albo po operacji przetwarzania. Ze względu na wydajność przetwarzania zalecane jest zawsze stosowanie Watermark dla źródła. Przykład drugiego zastosowania (dodania watermark do operacji) pokazany jest poniżej:
Użycie WatermarkStrategy w ten sposób pobiera strumień i tworzy nowy strumień z elementami ze znacznikami czasu i znakami wodnymi. Jeśli oryginalny strumień miał już sygnatury czasowe i/lub znaki wodne, osoba przypisująca sygnaturę czasową nadpisuje je.
Monotonicznie rosnące znaczniki czasu
Najprostszym przypadkiem specjalnym generowania watermark jest sytuacja, w której znaczniki czasu widziane przez dane zadanie źródłowe występują w porządku rosnącym. W takim przypadku bieżący watermark może być przekazany, ponieważ wcześniejsze znaczniki czasu nie zostaną dostarczone.
Należy zauważyć, że konieczne jest tylko, aby sygnatury czasowe były rosnące również w przypadku równoległego źródła danych. Na przykład, jeśli w określonej konfiguracji jedna partycja Kafka jest odczytywana przez tylko jedną równoległą instancję źródła danych, konieczne jest jedynie, aby znaczniki czasu były rosnące w każdej partycji Kafki.
WatermarkStrategy.for_monotonous_timestamps() mechanizm łączenia znaków wodnych Flink generuje prawidłowe znaki wodne za każdym razem, gdy równoległe strumienie są łączone.
WatermarkStrategy.for_monotonous_timestamps()Stała długość opóźnień
Innym przykładem generowania watermark jest opóźnienie znaku wodnego w stosunku do maksymalnego opóźnienia. Ten przypadek obejmuje scenariusze, w których z góry znane jest maksymalne opóźnienie, jakie można napotkać w strumieniu, np. podczas tworzenia niestandardowego źródła zawierającego elementy ze znacznikami czasu rozłożonymi w ustalonym okresie czasu do testowania. W takich przypadkach Flink udostępnia generator BoundedOutOfOrdernessWatermarks, który przyjmuje jako argument maxOutOfOrderness, tj. maksymalny czas, przez jaki element może się spóźnić, zanim zostanie zignorowany podczas obliczania końcowego wyniku dla danego okna. Spóźnienie odpowiada wynikowi t - t_w, gdzie t jest znacznikiem czasu (czasu zdarzenia) elementu, a t_w znacznikiem czasu poprzedniego znaku wodnego. Jeśli opóźnienie jest większe niż maksymalne i element jest uważany za spóźniony to domyślnie jest ignorowany podczas obliczania wyniku zadania dla odpowiedniego okna.
WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(10))Przykład:
public class Watermark {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> inputStream = env.fromData(List.of("a", "bb", "ccc", "dddd", "eeeee", "fffffff"));
// Assign timestamps
DataStream<String> withTimestamps = inputStream
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofMillis(1))
.withTimestampAssigner((event, timestamp) -> LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) - event.length())
);
// Apply tumbling event-time window and reduce function
withTimestamps
.windowAll(TumblingEventTimeWindows.of(Time.milliseconds(1)))
.reduce(new ReduceFunction<String>() {
@Override
public String reduce(String a, String b) {
return "res";
}
})
.print();
env.executeAsync("Windowed MyEvent Stream");
Thread.sleep(2000);
}
}Exercise
Uruchom klasę Watermark. Niestety trudno w tym wypadku wymusić nam zakończenie okna i wywołanie przetwarzania.
Lateness
Domyślnie późne elementy są usuwane, gdy znak wodny znajdzie się poza końcem okna. Jednak Flink pozwala określić maksymalne dozwolone spóźnienie dla operatorów okien. Dozwolone opóźnienie określa, o ile czasu elementy mogą się spóźnić, zanim zostaną usunięte, a jego domyślna wartość to 0. Elementy, które pojawiają się po tym, jak znak wodny minie koniec okna, ale zanim minie koniec okna, plus dozwolone opóźnienie, są nadal dodawane do okna. W zależności od użytego wyzwalacza spóźniony, ale nie upuszczony element może spowodować ponowne uruchomienie okna. Tak jest w przypadku EventTimeTrigger.
Wyzwalacze okien
Każde okno ma tzw. Trigger (wyzwalacz) i funkcję przetwarzania (ProcessWindowFunction, ReduceFunction lub AggregateFunction). Funkcja będzie zawierać obliczenia, które mają zostać zastosowane do zawartości okna, podczas gdy Trigger określa warunki, w których okno jest uważane za gotowe do zastosowania funkcji.
Zasady wyzwalania mogą wyglądać następująco: „kiedy liczba elementów w oknie jest większa niż 4” lub „kiedy znak wodny przechodzi przez koniec okna”. Wyzwalacz może również zdecydować o wyczyszczeniu zawartości okna w dowolnym momencie między jego utworzeniem a usunięciem. Czyszczenie w tym przypadku odnosi się tylko do elementów w oknie, a nie do metadanych okna. Oznacza to, że wciąż można dodawać nowe dane do tego okna.
Assigner - przypisanie do okna
WindowAssigner jest odpowiedzialny za przypisanie każdego przychodzącego elementu do jednego lub większej liczby okien.
Flink jest dostarczany z predefiniowanymi narzędziami do przypisywania okien dla najczęstszych przypadków użycia, a mianowicie Tumbling Window, Sliding Window, Session Window i Global Window.
Możesz także zaimplementować niestandardowy program przypisujący okna, rozszerzając klasę WindowAssigner. Wszystkie wbudowane narzędzia przypisujące okna (z wyjątkiem okien globalnych) przypisują elementy do okien na podstawie czasu, który może być czasem przetwarzania lub czasem zdarzenia.
Okna oparte na czasie mają początkowy znacznik czasu (włącznie) i końcowy znacznik czasu (wyłączny), które razem opisują rozmiar okna. W kodzie Flink używa TimeWindow podczas pracy z oknami opartymi na czasie, które mają metody do sprawdzania początkowego i końcowego znacznika czasu, a także dodatkową metodę maxTimestamp(), która zwraca największy dozwolony znacznik czasu dla danego okna.
TumblingWindow
TumblingWindow assiner przypisuje każdy element do okna o określonym rozmiarze. Tumbling okna mają stały rozmiar i nie zachodzą na siebie. Na przykład, jeśli utworzymy okna o rozmiarze 5 minut, bieżące okno zostanie przetworzone, a nowe okno będzie uruchamiane co pięć minut, jak pokazano na poniższym rysunku.

Exercise
Uruchom program TublingWindow.java
Przedziały czasu można określić za pomocą jednej z następujących opcji: Time.milliseconds(x), Time.seconds(x), Time.minutes(x), i tak dalej.
SlidingWindow
Okna przesuwne to także okna o stałej długości. Dodatkowy parametr Sliding Window określa, jak często okno przesuwane jest uruchamiane. W związku z tym przesuwne okna mogą zachodzić na siebie, jeśli przesunięcie jest mniejsze niż rozmiar okna. W takim przypadku elementy są przypisane do wielu okien.
Na przykład możesz mieć okna o rozmiarze 10 minut, które przesuwają się o 5 minut. Dzięki temu co 5 minut otrzymujesz okno zawierające zdarzenia, które nadeszły w ciągu ostatnich 10 minut, jak pokazano na poniższym rysunku.

Exercise
Uruchom program SlidingWindow.java
Przedziały czasu można określić za pomocą jednej z następujących opcji: Time.milliseconds(x), Time.seconds(x), Time.minutes(x), i tak dalej.
SessionWindow
Osoba przypisująca okna sesji grupuje elementy według aktywności sesji. Okna sesji nie nakładają się na siebie i nie mają ustalonego czasu rozpoczęcia i zakończenia, w przeciwieństwie do okien timbling i sliding. Zamiast tego okno sesji zamyka się, gdy nie otrzymuje elementów przez określony czas, tj. gdy wystąpiła przerwa bezczynności. Narzędzie przypisujące okno sesji można skonfigurować ze statyczną przerwą w sesji lub z funkcją wyodrębniania przerw w sesji, która określa, jak długi jest okres nieaktywności. Po upływie tego okresu bieżąca sesja zostaje zamknięta, a kolejne elementy zostają przypisane do nowego okna sesji.

Exercise
Uruchom program SessionWindow.java
Przedziały czasu można określić za pomocą jednej z następujących opcji: Time.milliseconds(x), Time.seconds(x), Time.minutes(x), i tak dalej. Dynamiczne luki są określane poprzez implementację interfejsu SessionWindowTimeGapExtractor.
GlobalWindow
Globalne okna przypisują wszystkie elementy z tym samym kluczem do tego samego pojedynczego okna globalnego. Ten schemat okien jest użyteczny tylko wtedy, gdy określisz także wyzwalacz niestandardowy. W przeciwnym razie żadne obliczenia nie zostaną wykonane, ponieważ globalne okno nie ma naturalnego końca, na którym moglibyśmy przetwarzać zagregowane elementy.

Exercise
Uruchom program GlobalWindow.java
Wyzwalacze (trigger)
Wyzwalacz określa, kiedy okno (utworzone przez osobę przypisującą okno) jest gotowe do przetworzenia przez funkcję okna. Każdy WindowAssigner jest dostarczany z domyślnym wyzwalaczem. Jeśli domyślny wyzwalacz nie odpowiada Twoim potrzebom, możesz określić niestandardowy wyzwalacz.
Interfejs wyzwalacza ma pięć metod, które pozwalają wyzwalaczowi reagować na różne zdarzenia:
Metoda onElement() jest wywoływana dla każdego elementu dodawanego do okna. Metoda onEventTime() jest wywoływana, gdy uruchamiany jest zarejestrowany licznik czasu zdarzenia. Metoda onProcessingTime() jest wywoływana po uruchomieniu zarejestrowanego licznika czasu przetwarzania. Metoda onMerge() jest odpowiednia dla wyzwalaczy stanowych i łączy stany dwóch wyzwalaczy podczas łączenia odpowiadających im okien, np. podczas korzystania z okien sesji. Na koniec metoda clear() wykonuje wszelkie działania wymagane po usunięciu odpowiedniego okna.
W przypadku powyższych metod należy zwrócić uwagę na dwie rzeczy:
Pierwsze trzy decydują, jak działać na zdarzeniu inwokacji, zwracając TriggerResult. Akcja może być jedną z następujących:
CONTINUE: nic nie rób, FIRE: uruchom obliczenia, PURGE: wyczyść elementy w oknie i FIRE_AND_PURGE: uruchom obliczenia i wyczyść elementy w oknie później.
Flink ma kilka wbudowanych wyzwalaczy.
EventTimeTrigger uruchamia się na podstawie postępu czasu zdarzenia mierzonego znakami wodnymi. ProcessingTimeTrigger uruchamia się na podstawie czasu przetwarzania. CountTrigger jest uruchamiany, gdy liczba elementów w oknie przekroczy podany limit.
Funkcje przetwarzania
Po zdefiniowaniu okna musimy określić obliczenia, które chcemy wykonać na każdym z tych okien. Jest to obowiązkiem funkcji okna, która jest używana do przetwarzania elementów każdego okna, gdy system ustali, że okno jest gotowe do przetwarzania (inaczej zostanie uruchomiony wyzwalacz przetwarzania).
Funkcja okna może być jedną z funkcji ReduceFunction, AggregateFunction lub ProcessWindowFunction. Pierwsze dwa można wykonać wydajnie, ponieważ Flink może stopniowo agregować elementy dla każdego okna, gdy tylko się pojawią. Funkcja ProcessWindowFunction pobiera obiekt Iterable dla wszystkich elementów zawartych w oknie oraz dodatkowe metainformacje o oknie, do którego należą te elementy.
Reduce Function
ReduceFunction określa, w jaki sposób dwa elementy z danych wejściowych są łączone w celu utworzenia elementu wyjściowego tego samego typu. Flink używa funkcji ReduceFunction do przyrostowego agregowania elementów okna.
Funkcja ReduceFunction może być zdefiniowana i używana w następujący sposób:
withTimestamps
.windowAll(TumblingEventTimeWindows.of(Time.milliseconds(1)))
.reduce(new ReduceFunction<String>() {
@Override
public String reduce(String a, String b) {
return "res";
}
})
.print();Aggregate Function
Funkcja AggregateFunction jest uogólnioną wersją funkcji ReduceFunction, która ma trzy typy: typ wejściowy (IN), typ akumulatorowy (ACC) i typ wyjściowy (OUT). Typ wejściowy to typ elementów w strumieniu wejściowym, a funkcja AggregateFunction ma metodę dodawania jednego elementu wejściowego do akumulatora. Interfejs posiada również metody tworzenia akumulatora początkowego, łączenia dwóch akumulatorów w jeden akumulator oraz wyodrębniania wyjścia (typu OUT) z akumulatora. Jak to działa, zobaczymy na poniższym przykładzie.
Podobnie jak w przypadku funkcji ReduceFunction, Flink będzie stopniowo agregować elementy wejściowe okna w miarę ich nadejścia.
Funkcję AggregateFunction można zdefiniować i używać w następujący sposób:
// AverageAggregate same as before
public static class AverageAggregate implements AggregateFunction<Tuple2<Long, Integer>, Tuple2<Integer, Integer>, Double> {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0); // (sum, count)
}
@Override
public Tuple2<Integer, Integer> add(Tuple2<Long, Integer> value, Tuple2<Integer, Integer> acc) {
return Tuple2.of(acc.f0 + value.f1, acc.f1 + 1);
}
@Override
public Double getResult(Tuple2<Integer, Integer> acc) {
return acc.f1 == 0 ? 0.0 : ((double) acc.f0) / acc.f1;
}
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);
}
}ProcessWindowFunction
Funkcja ProcessWindowFunction otrzymuje obiekt Iterable zawierający wszystkie elementy okna oraz obiekt Context z dostępem do informacji o czasie i stanie, co zapewnia większą elastyczność niż inne funkcje okna. Odbywa się to kosztem wydajności i zużycia zasobów, ponieważ elementy nie mogą być agregowane przyrostowo, ale zamiast tego muszą być buforowane wewnętrznie, dopóki okno nie zostanie uznane za gotowe do przetworzenia.
Sygnatura ProcessWindowFunction wygląda następująco:
// Custom ProcessAllWindowFunction to compute average
public static class AverageProcessFunction extends ProcessAllWindowFunction<
Tuple2<Long, Integer>, // input type
String, // output type
GlobalWindow> { // window type
@Override
public void process(Context context, Iterable<Tuple2<Long, Integer>> elements, Collector<String> out) {
int sum = 0;
int count = 0;
for (Tuple2<Long, Integer> element : elements) {
sum += element.f1;
count++;
}
double average = count == 0 ? 0.0 : ((double) sum / count);
out.collect("Window fired: average = " + average);
}
}Evictor
Oprócz wyzwalaczy dla okien możemy określić Evictora, który będzie mógł usuwać elementy z okna po uruchomieniu wyzwalacza oraz przed i/lub po zastosowaniu funkcji.
Flink jest dostarczany z trzema wstępnie zaimplementowanymi evictorami. To są:
CountEvictor: utrzymuje określoną przez użytkownika liczbę elementów z okna i odrzuca pozostałe z początku bufora okna. DeltaEvictor: bierze DeltaFunction i próg, oblicza deltę między ostatnim elementem w buforze okna a każdym z pozostałych i usuwa te, których delta jest większa lub równa progowi. TimeEvictor: przyjmuje jako argument interwał w milisekundach i dla danego okna znajduje wśród jego elementów maksymalny znacznik czasu max_ts i usuwa wszystkie elementy ze znacznikami czasu mniejszymi niż max_ts - interwał.
Połączenie Flink z zewnętrznymi źródłami danych
Kafka
Aby połączyć się Flinkiem z zewnętrznym serwerem jako źródłem lub ujściem wykorzystujemy tzw. connectory.
W przypadku Kafki musimy zaimportować zależności.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.4.0-1.20</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>W plikach FlinkKafkaSaslSslConsumer.java oraz FlinkKafkaProducerSaslSsl.java znajdują się przykłady połączenia Flinka z Kafką na serwerze online: https://www.cloudclusters.io.